
Solutions
ServicesLighthouse Components
Case Studies
35+ Projects Delivered
Research
Technical Articles · 100+ PostsWhite Papers · Strategic BriefingsResearch · 3 Papers

The Thesis · 2026
The next architecture for SaaS — how software should work when AI is good enough to make decisions but not yet trusted enough to act alone.
AN IONIO STRATEGIC THESIS · OPEN SOURCE
Prescriptive intelligence is an open-source paradigm observed, called out & formalized for how software should work when AI is good enough to make decisions but not yet trusted enough to act alone.
By the time you are reading this, you will have already started to see it. Companies like <REDACTED>,<REDACTED> & <REDACTED> are doing it in their verticals. Others are shipping recommendation feeds where dashboards used to live. The patterns we talk about in this writeup are emerging independently across SaaS because the underlying problem is the same everywhere: platforms sit on years of data & obscured insights that their users never act on, because the software surfaces data instead of decisions.
My article is a systematic breakdown of that problem and the architecture that solves it.
We cover
SaaS CEOs, Heads of Product & AI at $3M-100M mid-market platforms sitting on gigabytes of cross-customer data will love this article. Your CTO and heads of engineering will want to pull their hair out. 💀
A video version is out shortly.
My prediction: within 6 months of publication (April 2026), at least two major SaaS platforms reposition their primary user-facing surface from a dashboard to a prescription feed or an evolution of the same.
Most mid-market SaaS platforms are leaving 40–60% of potential ARR on the table. The unlock is a pricing tier nobody in the category has built yet.
The math runs the same shape across verticals. Mid-market platform: 2,000 merchants, $400/month average, $9.6M ARR. Add a strategic intelligence tier at $2,000/month, ship it to the 10–15% of the base that needs it, and that is $4M–$6M of net new ARR without adding a single merchant. Conservative, before retention compounds.
The mechanism is a pricing reframe. Traditional SaaS charges against the person it replaces an ops coordinator at $20–$60/hour. That ceiling is why mid-market plateaus at $200–$800/month no matter how many features get bolted on. Strategic intelligence replaces the person making the decision — a merchandising lead, a COO, salaries that run $250k–$800k loaded.
Here are some competitors 💀 companies already doing this:
More on the funding, pricing, and incumbent moves in the EV section below.
The software stops competing with the next app in the category. It is competing with a salary.
NRR climbs because customers attributing real dollars to the platform do not churn, they expand. The multiple expands because SaaS sold on outcomes trades higher than SaaS sold on seats. Even a 1x multiple jump on a $15M ARR book is $15M of enterprise value created from nothing but a pricing architecture change.
The architecture that lets you charge for outcomes, that turns dashboards into decisions and decisions into attributed revenue, is what the rest of this document describes.
We call it prescriptive intelligence.
Prescriptive intelligence is a paradigm for building software that thinks on behalf of its users.
Anyone can build it. Here is how it works.

Step 1 — The data layer. You take everything the platform already collects, transactional data, behavioral patterns, product catalogs, customer histories, and aggregate it into one cohesive data layer. Not siloed in different products or acquired entities.
One single source of truth that the AI can reason across as context.
Step 2 — The context layer. On top of that data, you layer in what we call tribal knowledge(?) the customer's SOPs, return policies, support scripts, past decisions, pricing logic, style guides, educational material.
This is what tells the system what "right" looks like for that specific customer, not just what the data says in aggregate. Almost no platform treats this as a first-class data source today.
Step 3 — The reasoning engine. On top of both, you add a reasoning engine (SOTA reasoning LLM) that diagnoses problems, compares against cohorts, runs the math on potential interventions, and surfaces a ranked set of decisions with projected impact. It’s a mix of LLM + ML models.
These three steps are what make up prescriptive intelligence. The details of each layer are covered in Section 5.
Here is what it looks like for the user.
The user sees a feed of “prescription cards” ranked, prioritized, each one a specific decision the system is recommending. The UI shows charts when you need comparisons. Timelines when you need sequencing. Side-by-side projections when you need tradeoff analysis.
See a demo here.
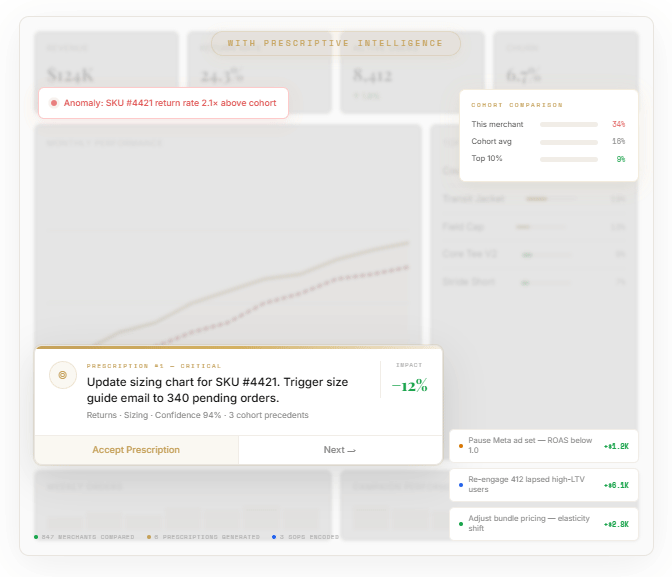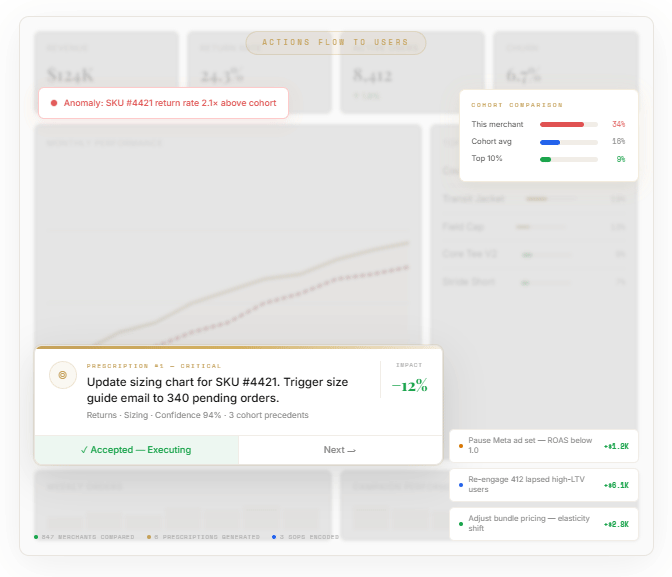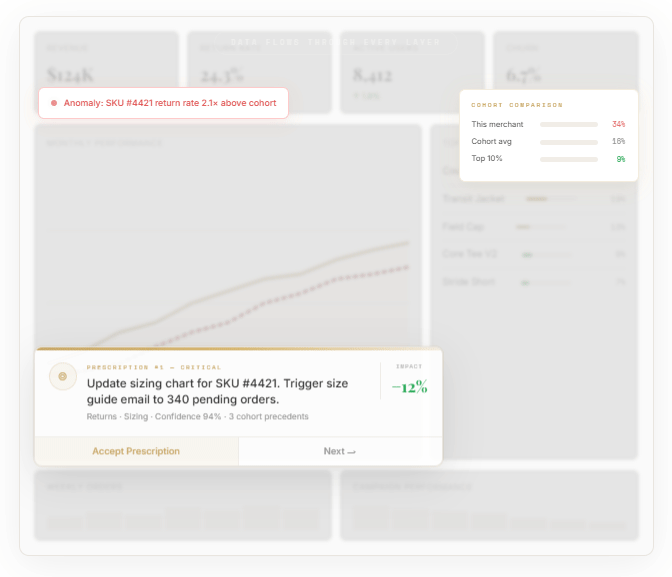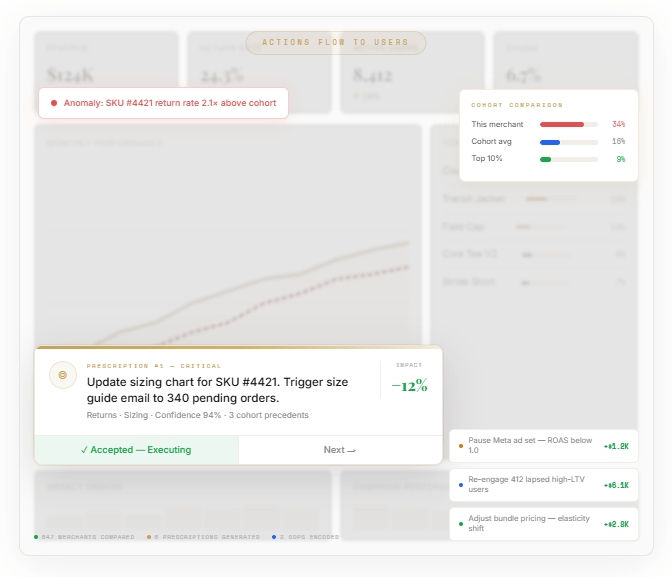
The atomic unit is the “prescription card”. Every recommendation follows the same anatomy:
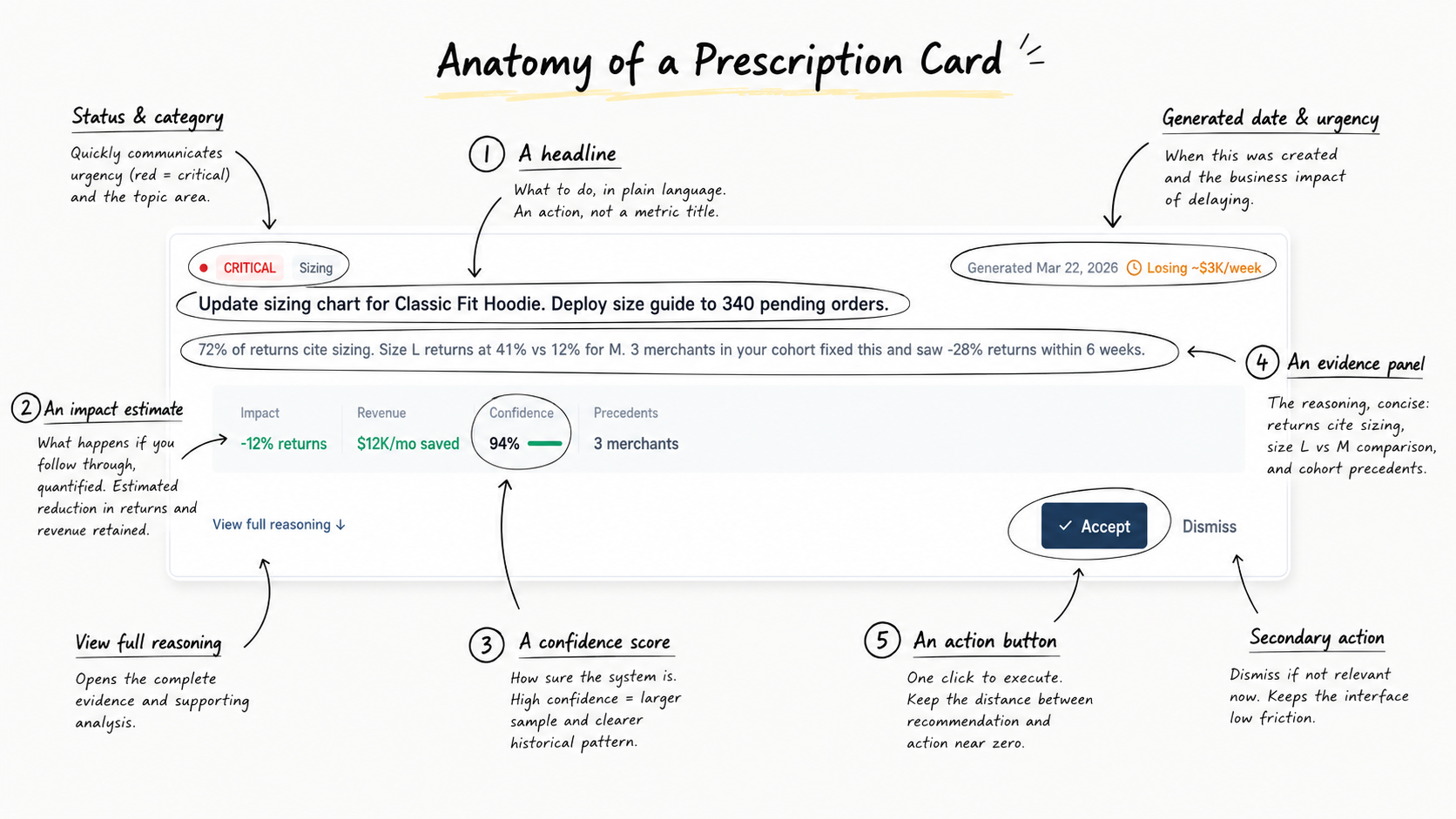
A headline. What to do, in plain language. An action, not a metric title. "Update the sizing chart for SKU-4421." "Pause the underperforming ad set and reallocate spend."
An impact estimate. What happens if you follow through, quantified. "Estimated to reduce returns by 12% for this SKU, roughly $14,000 per quarter in retained revenue." A number, not a platitude.
A confidence score. How sure the system is. High confidence means large sample, clear historical pattern. Medium means the data supports it but the signal is weaker. Low means potential impact is high but the system is working with limited data.
An evidence panel. The reasoning, concise. "847 returns in the last 90 days cited 'too small.' Customers who exchanged for a size up had a 91% keep rate. Three cohort precedents saw 19–27% return reductions within 60 days."
An action button. One click to execute. The distance between recommendation and execution is as close to zero as possible.
Every post-purchase platform today shows roughly the same thing. A returns portal with three buttons: refund, exchange, store credit. A dashboard showing return rates and top reasons. The merchant nods, maybe exports a CSV, closes the tab. The return still happened. It will happen again tomorrow, from the same SKU, for the same reason.
With a prescriptive intelligence layer, the system scans the merchant's return history, identifies that SKU-4421 is returning at 2.1x the category average, reads 847 returns citing "too small," cross-references against fit data, checks what happened when three other merchants had the same pattern — and surfaces a card:
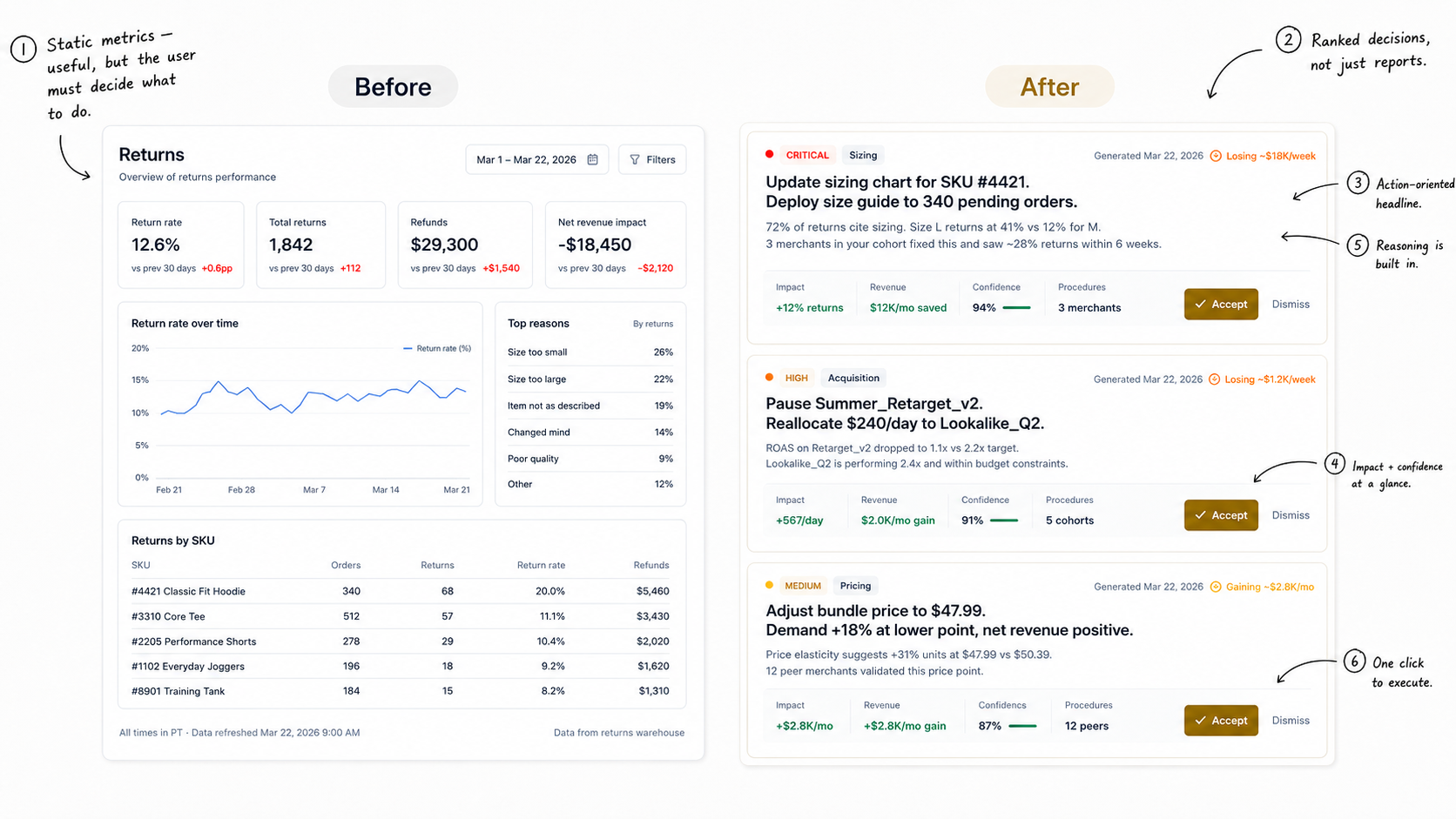
One click. The size chart updates. The email goes out. The system tracks the outcome over 60 days and feeds the result back into the model.
PS. our companion article, on prescriptive intelligence as applied in the post-purchase category, should be out shortly. It takes this framework into that vertical with named companies, a tier-by-tier feature matrix, and company-specific prescriptions. It will be relevant read.
In 2023, we started reaching out to SaaS companies to help them implement AI. We treated it like an open-ended problem. We got on calls with bootstrapped startups, mid-market platforms, and public companies — dozens of them across revenue ranges, categories, and technical maturity. The question we were trying to answer was not "where can we add AI?" That question is easy. Everybody can answer that question. The question we were trying to answer was: where does AI create revenue that did not exist before?
Not just the typical PR bump from announcing an AI feature or the marketing push of adding a co-pilot badge to the website. We wanted to find the place where the AI capability, once shipped, would generate attributable dollars. new retained revenue, reduced cost - that the platform could measure and charge for.
We always struggled to find meaningful opportunities.
Primarily this was because the models were just not good enough yet. GPT-3.5 was SOTA back then. Models hallucinated constantly. Context windows were tiny and the reasoning was shallow. The things you could build with that generation of intelligence were limited to what they were: autocompletes, subject-line writers, message drafters, smart search bars, FAQ chatbots. Useful features. Not transformative ones. Not the kind of capability that changes a platform's competitive position or unlocks a new pricing tier.
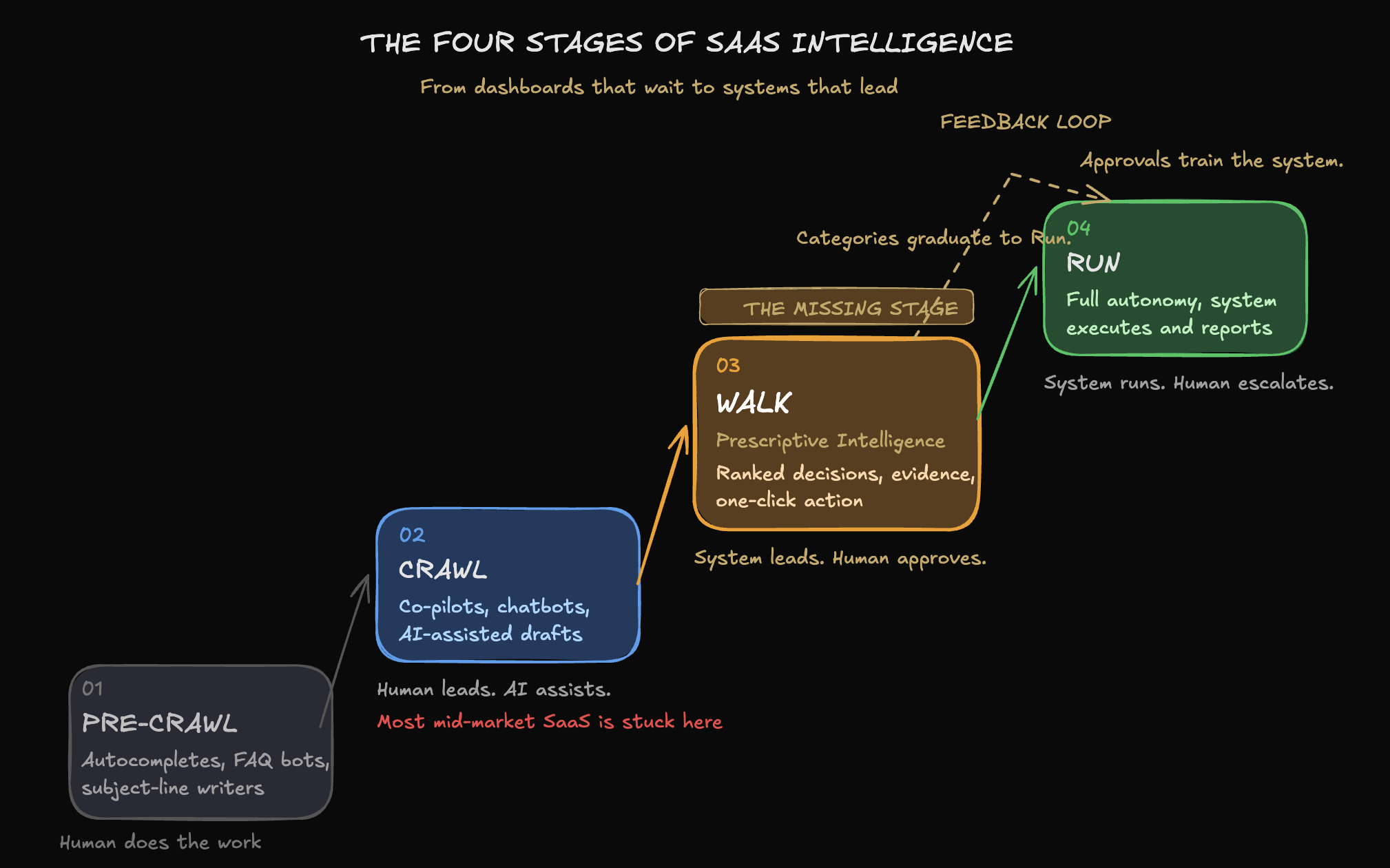
That was the first stage. Call it the pre-crawl — AI features that every SaaS company has already shipped or can ship in a weekend with today's tooling. These features are table stakes. They are no longer differentiating. They are done.
Then came 2024. Models got meaningfully smarter. Context windows expanded. Tool use and function calling became reliable. And the industry arrived at the architecture that matched the moment: co-pilots. We started building them in early 2024. They started making real sense by late 2024, early 2025. A co-pilot is an intelligent layer that sits alongside the user — it can draft, suggest, summarize, answer questions, accelerate workflows. The user stays in the driver's seat. The AI assists.
Co-pilots were the crawl stage. And they were the right answer for their moment. When models were smart enough to be useful but not reliable enough to be trusted, putting a human in the loop was the correct architectural decision. Every major SaaS platform adopted this pattern. Dashboards got chatbot overlays. Workflows got AI suggestions. Support tools got draft-response copilots. The entire category moved in lockstep.
A co-pilot is, by definition, a system that waits. For the user to ask. For the merchant to compose a question. For someone to log in. The intelligence is present but passive. That is the problem.
Software is supposed to be autonomous. If the system has access to your data and can reason about outcomes, it should be operating, not idling until a human types a question into a chat window. The destination is clear — twelve months ago this was a fringe idea among VCs and thought leaders; today Tobi Lütke talks about it and every SaaS vertical has its own word for it ("agentic" in e-commerce, "autonomous agents" in CRM, "self-driving workflows" in operations, "AI-native" in marketing).
Nobody can get there. The reasons — models, data, liability — are detailed in the next section. The point for now is that the industry is stuck. Platforms have left crawl and cannot reach run. The platforms that tried to skip ahead and jump straight to run have made it worse for themselves.
What happens when a SaaS company declares its product "autonomous" or "agentic" before the product can back it up is predictable and damaging. The marketing team writes positioning copy around outcomes and autonomy. The sales team starts selling a vision the product team has not shipped. The product pages describe an experience the customer cannot find when they log in. And the customer — the person actually paying — is left staring at a dashboard that looks the same as it did last quarter, wondering what exactly changed.
This is the specific failure mode: the company cannot articulate what the AI actually does. Not in a way a user can see, touch, or verify. "Our platform uses AI to optimize your workflow" is not a product description. It is a press release. Users have been sold "outcomes" and "benefits" for years. They are tired of it. They do not want to hear that the software will magically improve their numbers. They want to see what the product looks like. They want to understand the mechanism. They want to click something and watch it work. And when the product behind the positioning is a chatbot layered over the same data they already had, or an "intelligence" feature that exists in documentation but not in the interface, the gap between promise and experience erodes trust faster than the AI can build it.
This is not a messaging problem. It is a structural one. No one — not users, not the platforms themselves, not the market — believes that AI in any vertical is ready to run a business operation unsupervised. That belief may be wrong in eighteen months. It is correct today. And companies that position as if it is already true are not ahead of the market. They are destabilizing their own product narrative, confusing their existing customers, and making the eventual transition harder because they have already burned the credibility they will need when the capability is actually ready.
You cannot jump from crawl to run. The gap is too wide, the trust is too thin, and the product evidence does not exist yet. If you try, you get the worst possible outcome: a company whose marketing says autonomous, whose product says co-pilot, and whose customers say "I don't really understand what this does."
There has to be an intermediary step.
There is a missing stage. Between crawl and run. Between the co-pilot that waits and the autonomous system that acts. A stage where the platform surfaces decisions — not data, not dashboards, not chatbot responses — with projected impact, evidence, and a one-click action path. The user approves, rejects, or defers. Every response trains the system. Over time, high-confidence decisions graduate to autonomous execution. The prescription queue shrinks. The autonomous queue grows. The human's role shifts from operator to reviewer to, eventually, exception handler.
We call this prescriptive intelligence. It is the walk stage.
We did not arrive at this from theory.
We arrived at it from the work — dozens of SaaS conversations across verticals, failed experiments with chatbots and dashboards, and a realization that kept recurring: the best software is software the user never needs to log into.
The architecture applies wherever a SaaS platform has cross-customer data density and measurable outcomes. Merchandising, retail media, marketing ops, post-purchase e-commerce, insurance, community platforms — the crawl-walk-run progression applies across every vertical.
A companion article — Prescriptive Intelligence Applied: The Post-Purchase Category — takes this framework into the vertical where we have done the deepest work, with named companies, a tier-by-tier feature matrix, and company-specific prescriptions.
Open any e-commerce or retail SaaS website. Any vertical. Post-purchase, merchandising, email marketing, influencer platforms, POS systems, subscription management. Here is what you will observe.
Every single one of them is racing toward some version of autonomy. The language is everywhere — "agentic," "autonomous," "AI-native," "copilot," "intelligent assistant." In post-purchase you hear "agentic commerce operating system." In CRM, "autonomous sales agents." In marketing, "AI-powered campaign management." In operations, "self-driving workflows." Their intent is clear, how they get there is….well…???
There is a meaningful split happening in how companies are positioning against intent, and it matters.
Some companies have gone fully autonomous in their positioning. Not "we have AI features" — fully autonomous. Their entire website, their entire narrative, their entire brand is built around the idea that the software runs itself.
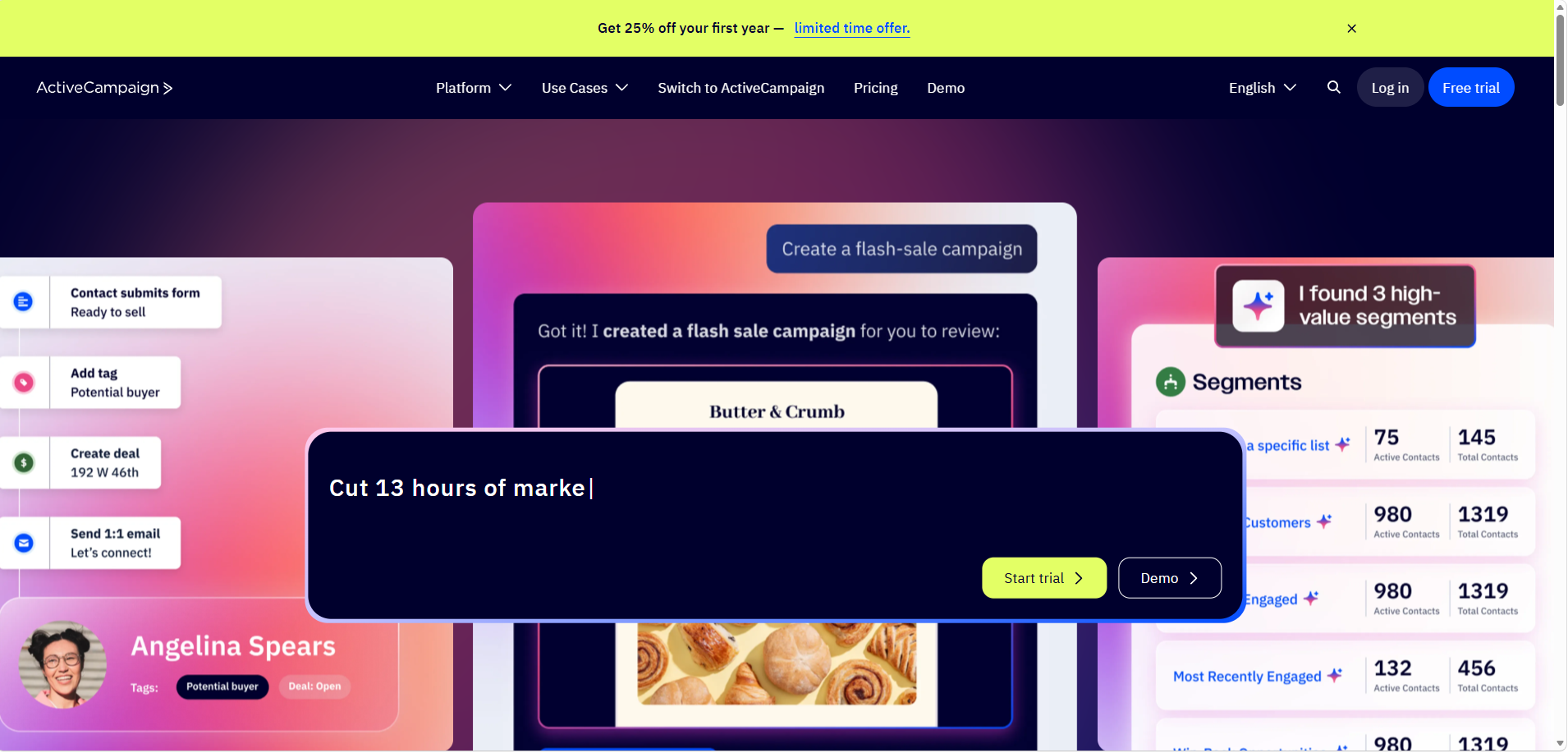
ActiveCampaign is now "the autonomous marketing platform."
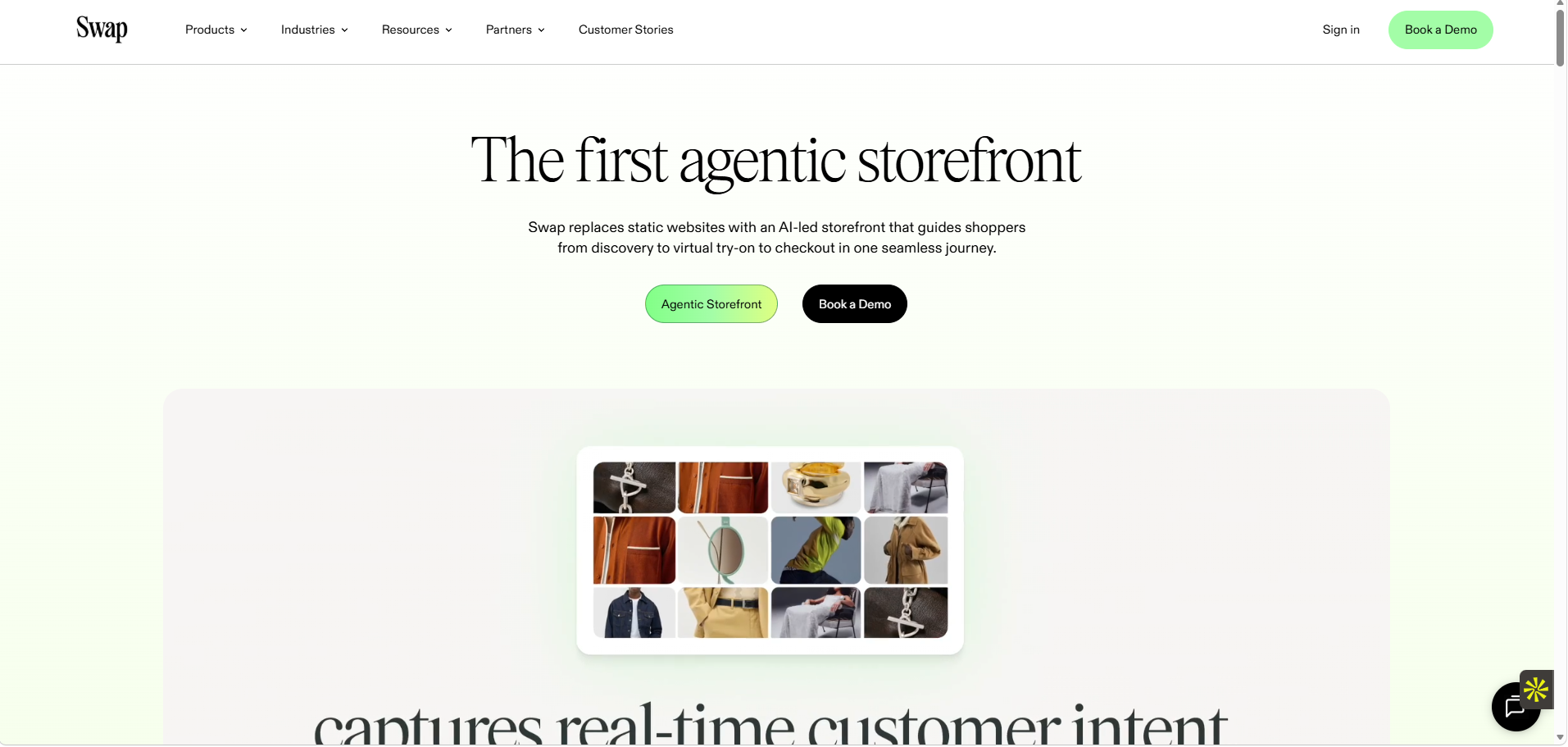
Swap Commerce is an "agentic commerce operating system."
These are literally their home-pages, this is the narrative being used to raise funding.
When a company goes that far with the autonomous story a very specific set of problems emerge.
Models are not reliable enough.
Not for end-to-end execution on business-critical decisions, not without human oversight. And even if they were, even if the models were perfect tomorrow, merchants would not let them do it.
A mid-market brand running $30M in annual revenue is not going to hand their return policy optimization, their carrier routing, their marketing spend allocation to a system that hallucinates occasionally and has no liability framework. They will work with AI. They will not hand over the keys. Not yet.
Data is not ready. (not for the reasons you think)
This is the one that does not get talked about enough. Most SaaS platforms — especially the ones that have grown through acquisition or rapid feature expansion - do not have a unified data layer. How do we know? Because we have asked.
They have separate apps with data buried in separate database instances, separate RDS clusters, separate schemas that were never designed to talk to each other.
Loop acquired Wonderment. Redo absorbed multiple tools. AfterShip bolted on returns alongside tracking and shipping. In each case, the data that would power a genuinely intelligent system is fragmented across systems that were built independently and integrated after the fact. There is no single source of truth. There is no cohesive intelligence layer. There are silos with bridges.
You cannot build an autonomous system on top of fragmented data. You can build a chatbot. You can build a dashboard. You cannot build a system that reasons across your entire customer journey when the data for that journey lives in four different databases with different schemas.
The liability is unresolved. When an AI makes a decision that costs a merchant money — switches a carrier that delays 10,00 packages, adjusts a return policy that spikes abuse, sends a campaign that tanks conversion, who is liable? The platform? The merchant who approved it? The model provider? There is no settled framework for this. And until there is, full autonomy carries legal exposure that no platform's general counsel will sign off on.
What follows is not conjecture, it’s my personal observation.
We have gone through hundreds of user reviews across multiple SaaS categories. In post-purchase e-commerce alone platforms like Narvar, parcelLab, AfterShip, Loop, Swap, you can read every G2 review, every Shopify app review, every public testimonial. Not a single merchant review says "I signed up, the system runs autonomously, and I am making more money." Not one.
The autonomous claims are on the marketing pages. They are not in the customer testimonials. Crazy, right?
What merchants actually praise is specific and operational: the returns portal, the tracking page, carrier coverage, the exchange flow, the Shopify integration, the customer support team. When they complain, they complain about analytics being slow, exports being limited, dashboards not being customizable. They are describing a product that gives them data and expects them to figure out what to do with it. That is basically a spreadsheet with better branding.
The pattern repeats outside e-commerce. Across CRM, across marketing platforms, across operations tools.
When you strip away the positioning and look at what users actually say they value and what they say they struggle with, the gap between the autonomous claims and the product experience is consistent. And if you are building “Agentic Intelligence” into your product, you know EXACTLY what we are talking about. 👁️
The absence of customer validation for autonomous claims is data.
“We will get there eventually.” “Product will catchup to the marketing soon”. It WILL but it has not yet, my exact point. In this doc we talk about how the product catches up to the marketing, fast in <8 weeks rather over multiple quarters or “eventually”
So…what actually happens to companies stuck in this gap is one of two things, and both are bad.
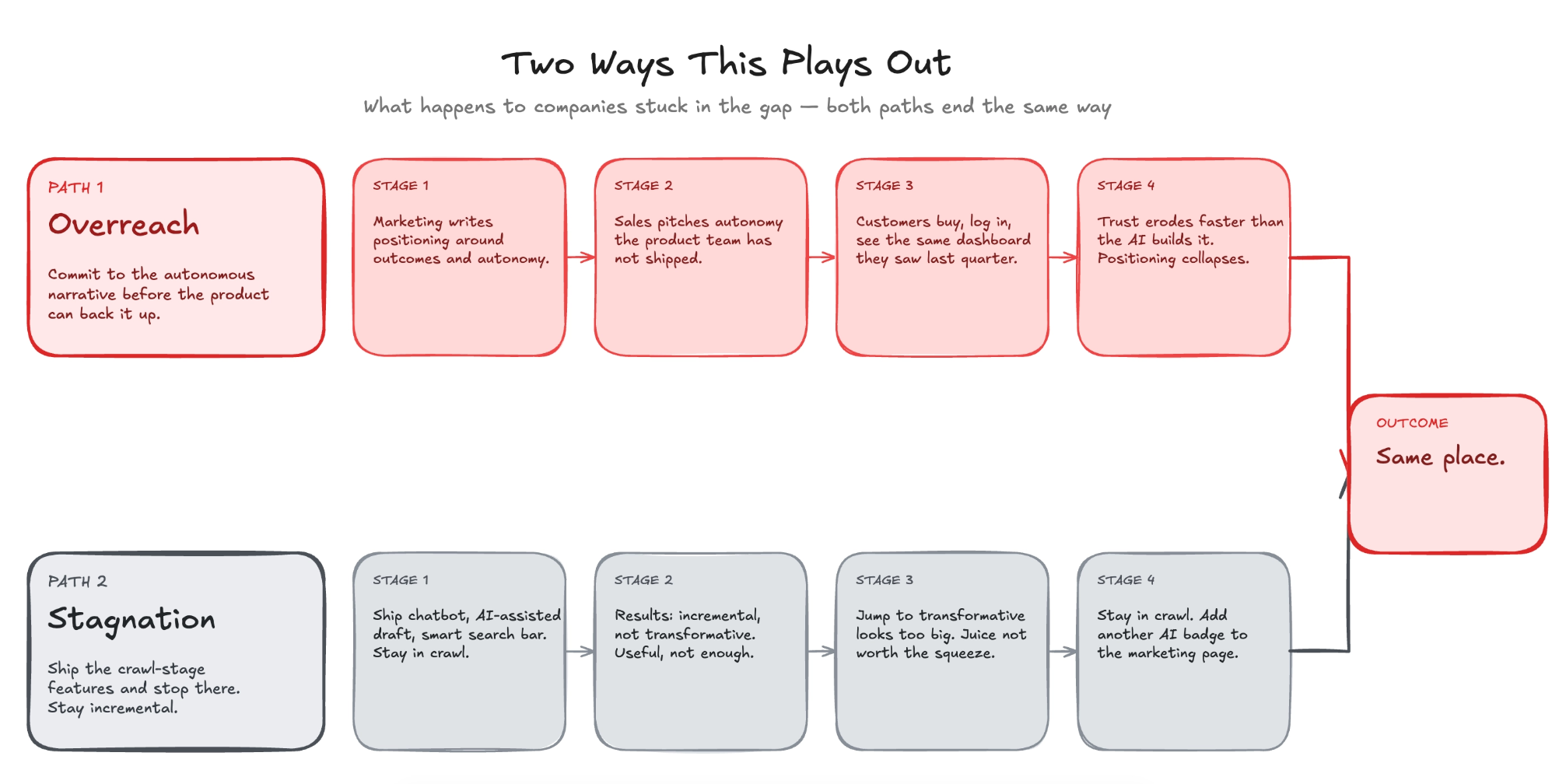
The first is overreach. The company commits to the autonomous narrative before the product can back it up. Like we described this in the previous section, the marketing team writes positioning around outcomes and autonomy, sales starts selling a vision the product team has not shipped. The customers book demos, some buy subs, then log in and see the same dashboard they saw last quarter lmfao. With some gimmicks
The company could not articulate what the AI actually does. not in any way a user can see or verify. Over time, the positioning erodes trust faster than the AI builds it. The company becomes a shell of what it once was…then poverty stagnation….or directly.
Second is stagnation (another way). The company shipps the crawl-stage features, the chatbot, the AI-assisted draft, the smart search bar, and finds that the results were incremental. Useful, but not transformative. Because the jump from incremental to transformative looks enormous (new data architecture, new pricing model, new org structure, new product surface), they decide the juice is not worth the squeeze. They stay in crawl. They ship more midtier features. They add another AI badge to the marketing page & watch the commoditization wave eat their differentiation from underneath them. From both sides, startups and incumbents.

Development velocity has collapsed. What took eighteen months takes weeks. Cursor, Claude Code, Codex, Shopify's own development acceleration.
Every SaaS founder in every category is living this. The implication is brutal: any feature that can be described as a workflow, a dashboard, a portal, a chatbot, or a rule-based automation is approaching zero as a differentiator. These are table stakes. Every competitor can ship them. A better-looking dashboard is not a competitive advantage. A more polished chatbot is not a moat.
The features that took years to build and millions to invest in are now reproducible in weeks by a focused team with modern tooling.
The platforms that acquired their way into capability breadth, the ones that bought the tracking company, the analytics startup, the AI-first specialist are feeling this double. Because in the post-Cursor world, a focused internal team can rebuild a specialist's capability faster than the acquirer can integrate the acquisition. The acquisition brought MRR and a customer base, but the technology it carried? That has a six-to-twelve month rebuild cost.
Every integration budget is a drag on velocity. Every acquired codebase is a second schema to harmonize, a second team to onboard, a second data model to reconcile.
The acquisitions that looked strategic in 2024 are starting to look expensive in 2026. Because the tech they paid far is….umm..pointless.
There is one more structural problem worth naming, because it sits underneath everything else.
The default mental model for AI integration is conversational. ChatGPT was a chat interface. "AI" became "I type, it responds." Every SaaS platform adopted it. Let's put a chatbot in the product. Let users ask questions about their data. Let's build a co-pilot.
A chatbot is a strange interface for a system that is supposed to be smarter than you. You are composing the questions. You are deciding what to ask and when. The system knows more than you do — it has access to all your data, all your history, all the cross-customer patterns — and it sits there idle, waiting for you to type something. What kind of intelligence is that?
The screen real estate problem alone should disqualify chat as the primary medium. A chat window is a narrow column of text. The decisions that matter in a business — carrier optimization, return policy changes, campaign budget reallocation, pricing adjustments — are complex, multi-variable, tradeoff-heavy. You need charts, comparisons, timelines, impact projections, evidence panels. The medium has to match the complexity of the decision. You can shove these into a chatbox. That is a duct-tape fix.
An autonomous system is an ecosystem, dozens of data feeds, inference layers, decision models, feedback loops, and action pathways running underneath a surface that the user barely needs to touch.
The user should NOT be driving this system.
The system should be driving itself.
It should be ingesting the data, identifying the patterns, modeling the outcomes, and surfacing the decisions that need human input, with the evidence for why, the projected impact of acting, and a one-click path to execute.
The human approves, rejects, or defers.
That is the interaction, the interace. The system leads and the human responds.
Conversation stays, but as a secondary mode. When the user wants to interrogate a recommendation, override a default, or explore a scenario, they can talk to the system.
But talking to the system is not the primary interaction. The primary interaction is the system telling the user what it found, what it recommends, and what happens if the user acts on it.
That is the architecture the industry needs. That is what we call the walk stage. And it is what the next section describes.
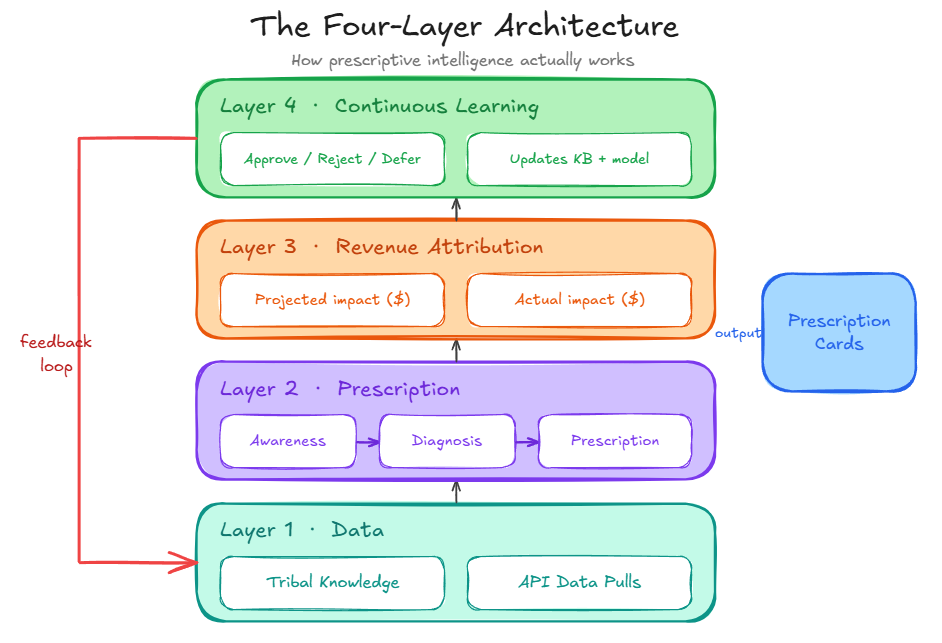
Prescriptive intelligence is a collection of formalized tools that implement the paradigm. Four layers. One output.
Pranav from our team released a boilerplate implementation of this architecture that any mid-market SaaS team can pull, read, and run.
The repo contains three things:
It's built specifically around the returns use case in post-purchase e-commerce, but the scaffolding is vertical-agnostic. A detailed video walkthrough of the code is coming out alongside this article.
The point of open-sourcing it is to make clear that this is not a slide-deck idea. The code runs. You can see it in action. The rest of this section walks through what each layer does.
Two kinds of data feed the system. Both matter equally.
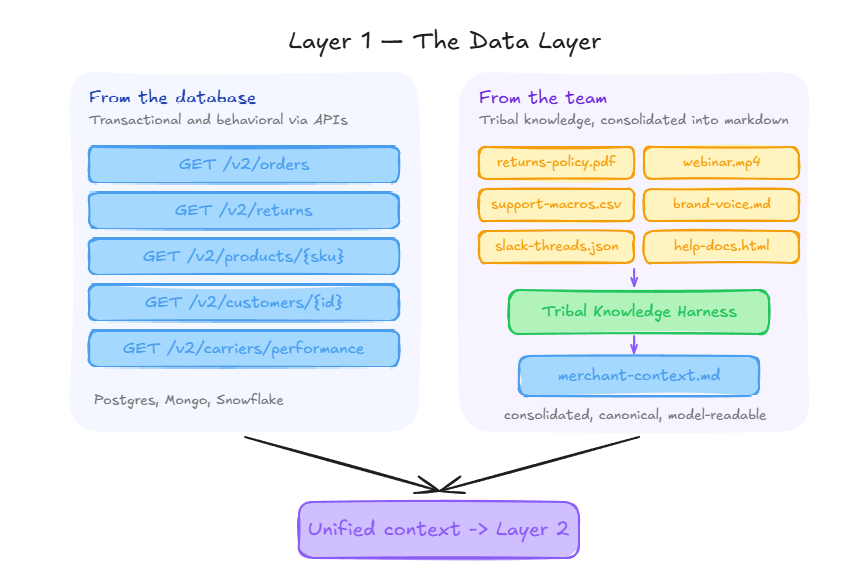
The first is transactional and behavioral data from the customer's own databases. Orders, returns, customers, products, carriers, campaigns. In the open-source repo this is mocked with JSON fixtures so you can run the full pipeline without wiring up a live database. In production it's pulled via APIs from whatever source of truth the customer uses.
The second is tribal knowledge. This is the one almost no SaaS platform treats as first-class data today. SOPs, return policies, support scripts, case studies, help docs, blog posts, webinar transcripts, style guides, past decisions. Everything that explains what "right" looks like for a specific customer in their voice, for their business.
Tribal knowledge starts out unstructured and scattered. It lives in Notion, Google Docs, Slack threads, YouTube recordings, people's heads. The harness Pranav built is what fixes that. You point it at your SOPs through a YAML config, it reads them, consolidates them into frameworks and decision rules, and produces one canonical markdown document that becomes the customer's operational context for every downstream prescription.
The YAML also defines what the system is allowed to do. What it can read. What it can write. Which actions auto-execute, which require approval, which are off limits. "Update product size chart" might be allowed. "Issue a refund over $500" might require a human. The permissions model lives next to the knowledge because both are part of the customer's operational context.
On top of the data layer sits a reasoning engine. A thinking model running three pipelines in sequence: awareness, diagnosis, prescription.
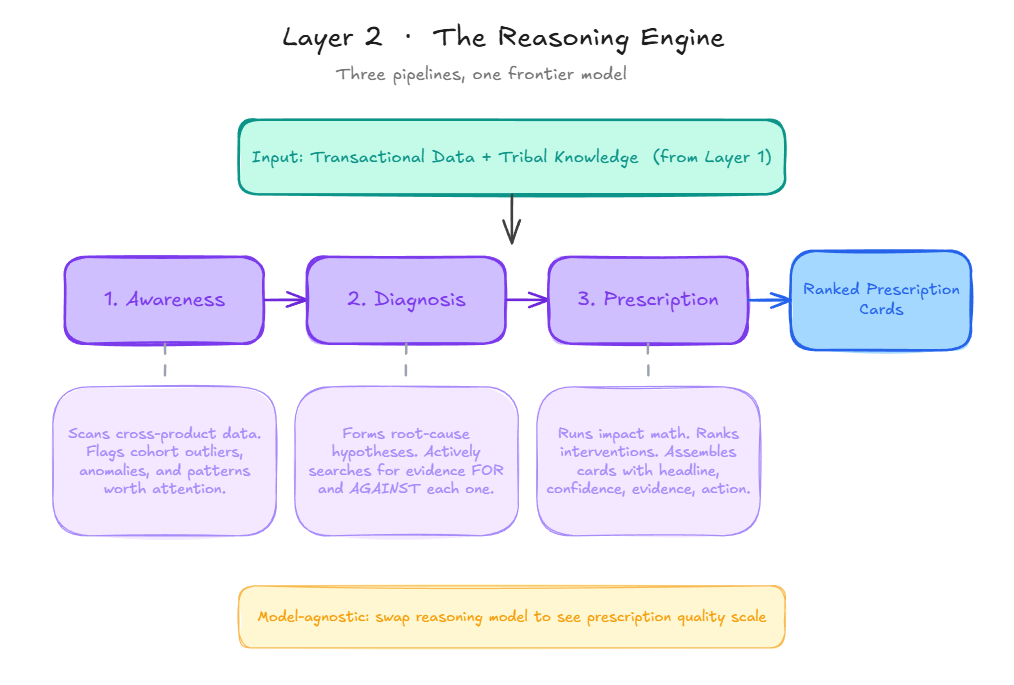
Awareness scans the transactional data and flags patterns worth attention.
Diagnosis forms hypotheses about root cause and actively searches for evidence both for and against each hypothesis, because a one-sided diagnosis produces bad prescriptions.
Prescription takes the diagnosis, runs impact math on possible interventions, and outputs ranked cards with the anatomy from Section 2.
The important thing here is what the SOPs are not. They are not if/then rules the model is pattern-matching against. They are flexible context. The model uses its own judgment, informed by tribal knowledge and the current data state, to produce prescriptions that are genuinely tailored. Two customers with similar return rates get different prescriptions because their policies, their margins, their brand voice, and their past decisions are different. The rigidity is in the card anatomy. Not the reasoning.
This means prescription quality scales with the reasoning model. A cheap model gets the direction right but misses nuance. It also tends to over-act — classifying a wrong-color return as a sizing issue, for example, because it wants to prescribe something rather than nothing. A frontier model catches the distinction. The reference implementation is model-agnostic by design, so you can swap models and see the delta yourself.
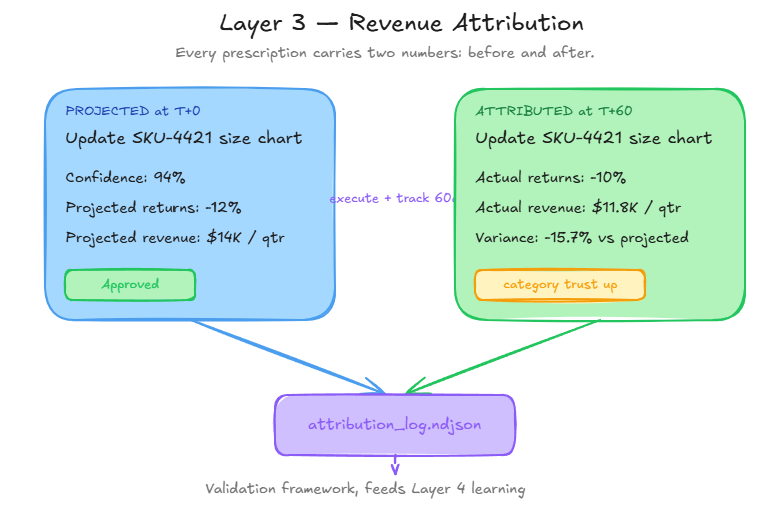
Every prescription carries two numbers. A projected impact before execution. An attributed actual after.
The projected number makes the card decision-grade. The merchant sees, in advance, what they stand to gain. The attributed number makes the pricing shift of Section 6 possible, because it closes the loop between "software made a recommendation" and "business outcome changed." Without attribution, prescriptions are suggestions. With attribution, they are investments with tracked returns.
Attribution is also what the validation framework in the open-source repo plugs into. You score prescription quality against synthetic cases before production, and attribution confirms or refutes that score once real customers start acting on real cards. Both halves of the loop need to work.
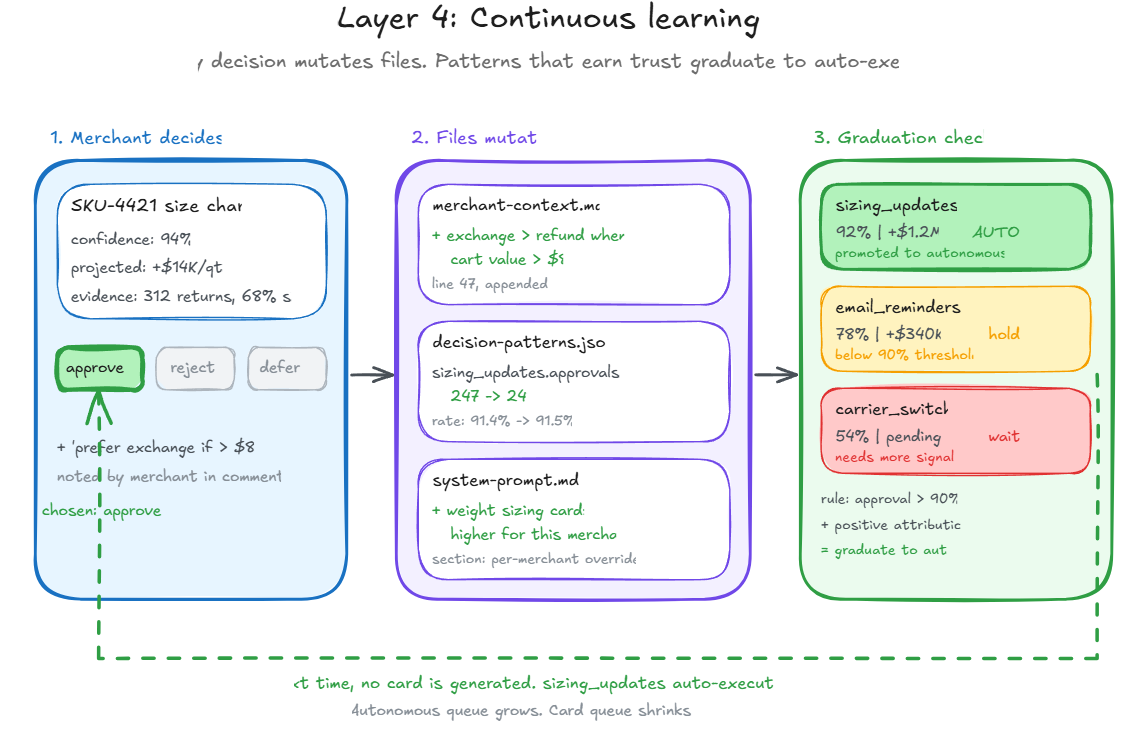
Every approval, rejection, and deferral updates two things. It updates the tribal knowledge, because a merchant's decision pattern is itself data about what "right" looks like for that specific customer. And it updates the prescription generation layer, because the model learns which categories, framings, and confidence bands get acted on versus ignored.
Over thousands of interactions, the system's model of the customer sharpens. Categories with high approval rates and positive attributed impact graduate to auto-execute, with human override retained. The prescription queue shrinks. The autonomous queue grows. You do not decide to become autonomous. You become autonomous because the learning layer earns it, one category at a time.
And as foundation models keep improving — longer context, better long-horizon reasoning, cheaper inference at quality — the learning layer starts surfacing patterns no human operator could hold in their head simultaneously. A merchant cannot track every return, every carrier, every campaign, every cohort, every policy change at once. The system can. That is the compounding advantage this architecture produces, and it is why the walk stage feeds naturally into run instead of requiring a leap.
We built a demo of this on prescriptiveintelligence.ai in late March 26’. It is an audiovisual walkthrough that shows what prescriptive intelligence actually feels like on a SaaS platform — the prescription feed, the card anatomy, the approval flow, the graduation to autonomy.
Most SaaS bills by feature, volume, or seat. Access to tools. Nobody in the pricing page owns the outcome.
It gets worse. SaaS categories consolidate. Point solutions get swallowed into larger suites. A single-problem SaaS is priced against the cheapest competitor or the cheapest line item in an incumbent's bundle. If your product can be described as a portal, a dashboard, or a workflow builder, someone is already rebuilding it at 60% of your price. That is the race to the bottom the crawl stage sits inside.
Prescriptive intelligence belongs to a broader category that is starting to emerge across SaaS. Call it strategic intelligence. Any tool whose primary output is a decision or an executed action, not a dashboard or a feature. Prescriptive intelligence sits here. So do autonomous agents that close loops end-to-end. So will most of the interesting software of the next five years.
The pricing for this category does not follow SaaS conventions.
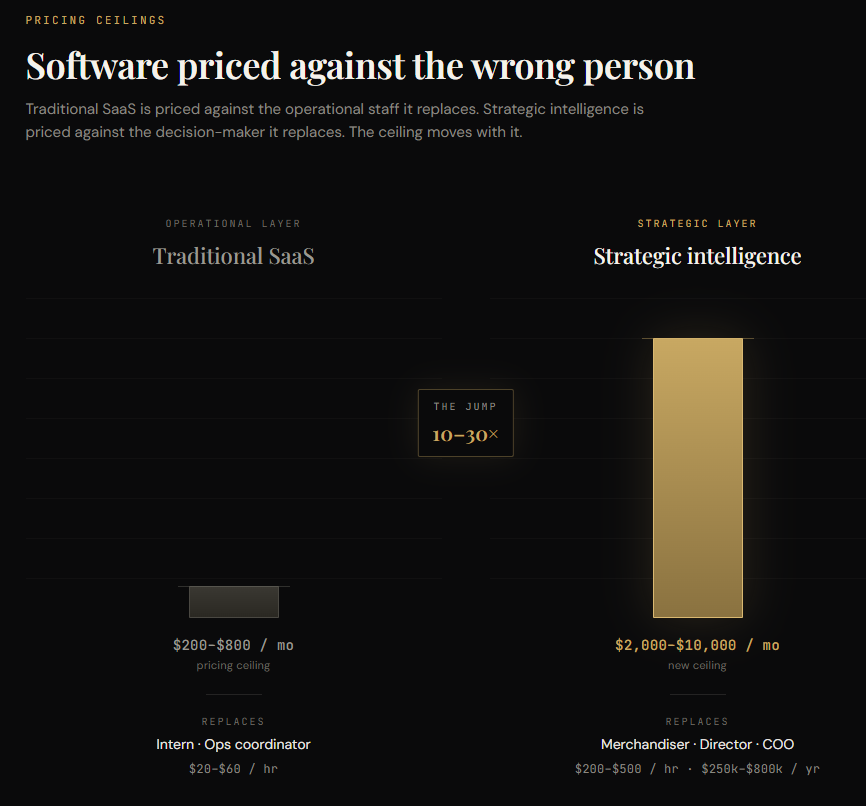
Traditional SaaS prices against the person it replaces. If the tool automates what an intern or an ops coordinator does, the ceiling is their hourly rate. $20–$60 an hour of busywork. That is why most mid-market SaaS plateaus at $200–$800/month per customer, no matter how many features get bolted on.
Strategic intelligence replaces the person making the decision. A merchandising lead. A campaign manager. A COO. Those people cost $200–$500 an hour loaded. A merchandising head runs $250k–$400k a year. A COO, double that. If the software is producing decisions of that quality at scale, it is no longer competing with the next app in the category. It is competing with a salary.
Take the same post-purchase platform from earlier. 2,000 merchants. Average $400/month. ~$9.6M ARR.
Before: pricing caps at $800/month top tier. A merchant doing $50M in GMV pays the same as one doing $150M. The value gap is huge. The pricing cannot capture it.
After: a strategic intelligence tier ships at $2,000/month, priced against decisions made, not features accessed. $2k is conservative if each card retains $10k–$50k a quarter in revenue. For the enterprise cut of the base, $5,000–$10,000/month is defensible. The tier is pitched not against the next app in the category. It is pitched against the in-house hire the merchant no longer needs to make.
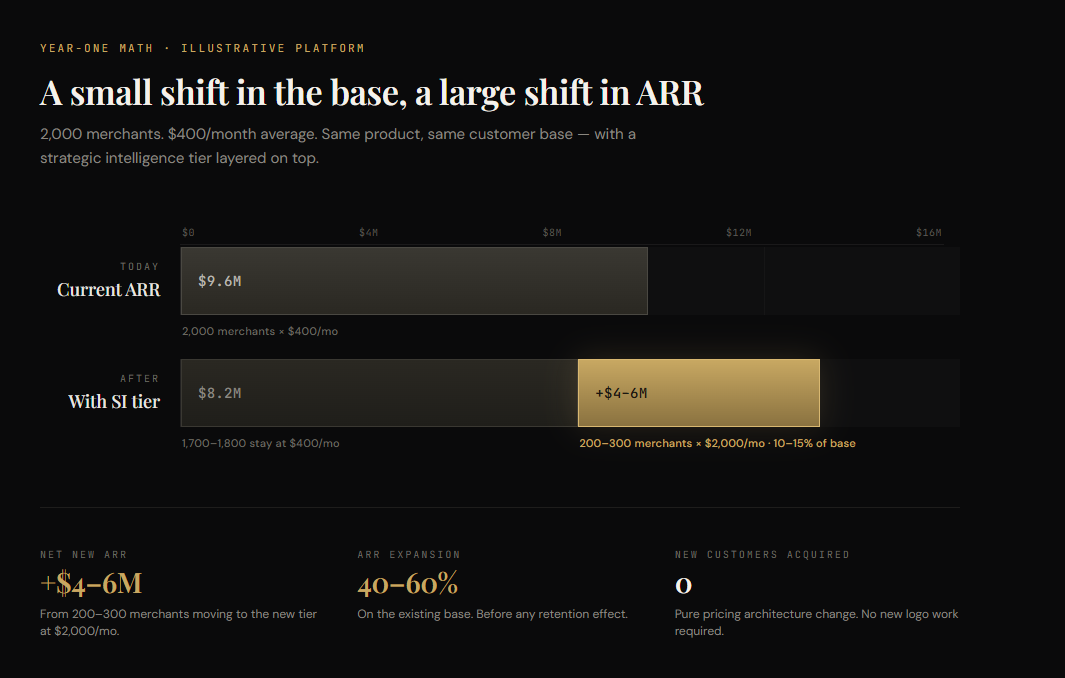
Adoption. Conservatively, 10–15% of the base moves to the new tier in year one. 200–300 merchants shifting from $400 to $2,000/month. Net new ARR: roughly $4M–$6M on top of a $9.6M base. A 40–60% expansion without adding a single new merchant.
That is before retention kicks in.
Strategic intelligence moves every input to enterprise value in the same direction. ARR expands because the new tier prints revenue that did not exist before. NRR climbs because customers who can attribute real dollars back to the platform do not churn — they expand. And the multiple expands because SaaS with rising NRR and pricing power built around outcomes trades higher than SaaS sold on features and seats.
You don't need a dramatic multiple jump for this to matter. Even a 1x expansion on the multiple, on a $15M ARR book, is $15M of enterprise value created from nothing but a pricing architecture change.
This is not a feature decision. It is a pricing decision, and the pricing decision is an enterprise value decision.
The pattern is already in motion:
Any SaaS that gets its first strategic intelligence tier into the market ahead of the category sets the price anchor for the rest of the vertical and compounds the advantage from there.
It is the highest-leverage move a mid-market SaaS CEO can make in the next 18 months.
The biggest mistake we see is handing strategic intelligence to the CTO and walking away. CEO reads an article like this one, forwards it to the head of engineering with "let's figure this out," considers their part done. Six months later: an intelligence feature that technically works in a demo, has nobody using it, and nobody paying extra for it.
The room was wrong.
Strategic intelligence is not just an engineering project. The word "just" is doing a lot of work in that sentence. Of course engineering is part of it. Models, pipelines, feedback loops, all of that has to work. But engineering is a load-bearing piece, not the whole building. The companies that have tried to ship this as a pure engineering function have the worst results, which is why so many AI features across SaaS look impressive in demos and disappear in production.
The most important thing we learned across dozens of these engagements: the beauty of building intelligence layers is how deeply you have to understand the business. You cannot engineer your way to a good prescription card. You have to understand why the merchant would care about it, what evidence would make them trust it, what action is most natural for them to take, and what happens after they take it.
Strategic intelligence is inherently a business project. You need ALL departments in the room, together, working and figuring out how to deliver intelligence to your customers.
Engineering is just the department that builds the product scaffolding around the raw intelligence.
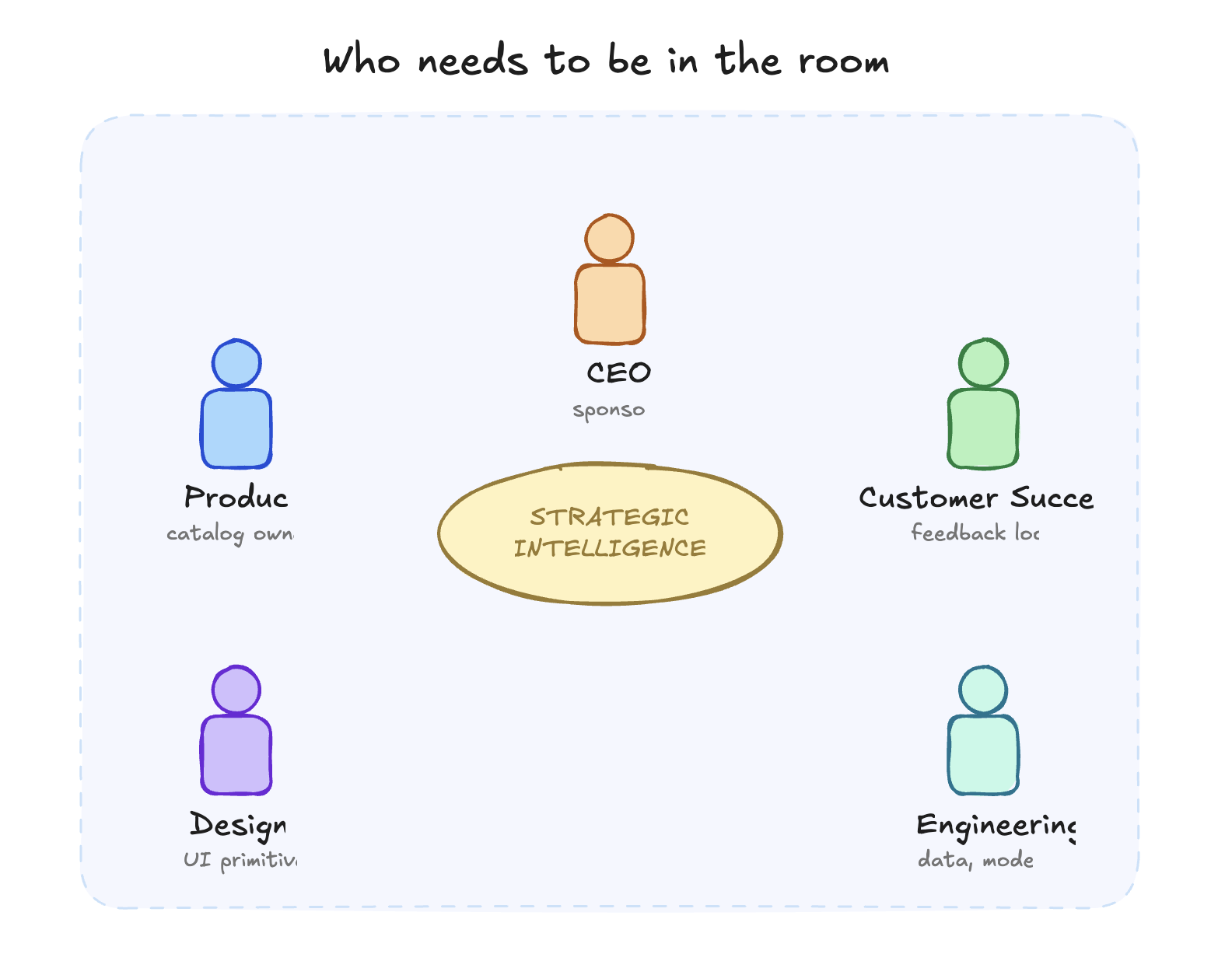
The CEO. Strategic intelligence changes what the product fundamentally is. It changes pricing, positioning, what you're selling, and who you're selling it to. This is not a product update. It is a strategic transformation. If the CEO is not sponsoring it, it will not ship in a way that changes the business.
Product. Every prescription is a product decision. What to surface, how, when, to whom. The prescription catalog is a roadmap of a fundamentally different kind than a feature roadmap, and somebody senior has to own it.
Customer Success. Merchants need to understand prescriptions, act on them, and provide the feedback that closes the loop. CS is where prescription quality gets validated in the real world. If CS is not in the room, prescriptions ship without context and get ignored.
Design. The prescription card is a new UI primitive. The difference between a signal-dense prescription and noise is largely a design problem. Get this wrong and the feed becomes another notification stream users learn to ignore.
Engineering and Data. The models, pipelines, feedback loops. These have to work. They are necessary. They are not sufficient.
Missing any of these seats produces the exact pathology visible across the industry today. Intelligence layers that technically exist but don't surface. Layers that surface without context. Layers that surface without an action the user can take.
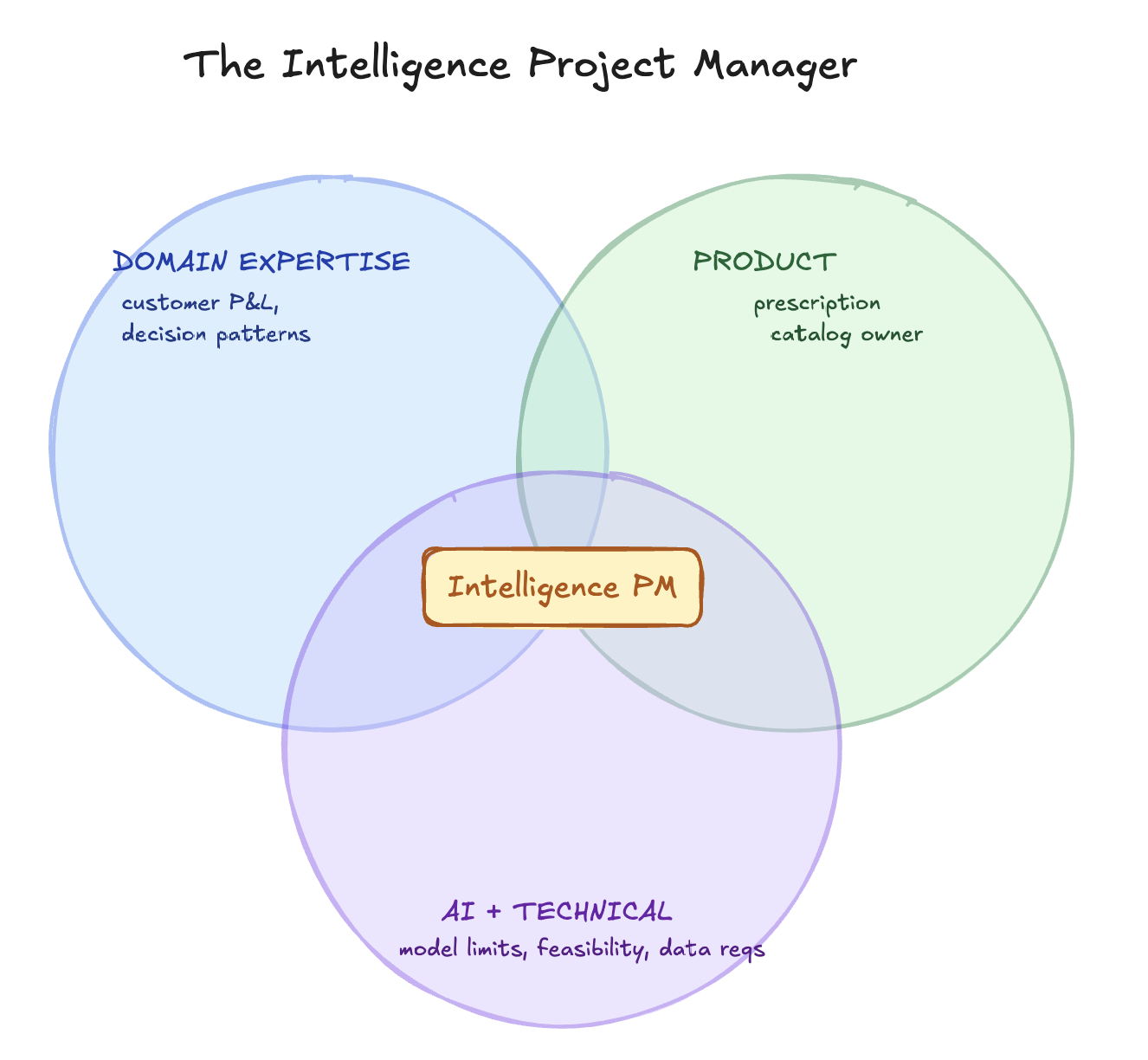
Out of this cross-functional pattern, a new role keeps emerging. One that did not exist in SaaS before.
The Intelligence PM is a specific kind of person. Not a job description you can write from a template.
This is someone who already lives in the new tooling. They use Claude, ChatGPT, Gemini, Lovable, Cursor as extensions of their own thinking. They talk to their computer. They prototype at the speed of thought. They understand, viscerally, that the process does not matter. The outcome does. When a task comes in, they do not ask how long it should take. They ask what the finished version looks like and work backwards from there.
They are cross-functional by instinct, not by job title. In a given week they might write a script, ship a landing page, run an outbound sequence, sit in a customer call, debug a data pipeline, and rewrite a piece of product copy. They understand every surface of the product, not because anyone told them to, but because they cannot build good prescriptions without understanding every place the prescription will land.
And they understand AI. Not at the "I read the ChatGPT blog" level. At the level of knowing what today's frontier models can reliably do, what they can't, and where the line moves next quarter. They can scope prescriptions that actually ship instead of ones that get stuck in research.
That person, rare as they are, becomes your Intelligence PM.
You will not find them on a standard PM job board. You will find them inside your own company already operating this way, or inside a peer company where they are underutilized, or running a small agency / indie project where they are sharpening this skillset alone. The hire is difficult. The alternative is worse: running your strategic intelligence initiative with a senior PM who treats it like a feature roadmap, or an ML engineer who treats it like a model-quality problem. Both fail in predictable ways.
Within 18 months, we believe this role becomes the highest-leverage hire in mid-market SaaS. Named or not, the companies that have one will pull ahead of the companies that don't.
By the time you've read this far, one of three reactions is already forming in your head.
One: "We're already doing this." A small group. You're running a version of this, or your product has drifted toward it organically, and this article is mostly labeling what you've built.
Two: "We're doing parts of it." Most of you. You have a data layer, some AI features, maybe recommendations in a roadmap doc somewhere. The architecture is not yet what we've described.
Three: "We're not doing any of this." You're still shipping dashboards and calling them intelligence. No feedback loop, no attribution, no cross-product data integration.
For the middle group, and especially for the first group (most of whom are doing less of this than they think), these are the ten questions worth answering honestly. Score each from 1 to 10.
Questions 4 and 8 are the sharp ones. Most readers will realize they have no way to answer them, because the systems that would produce those numbers do not exist in their stack yet.
That is the point. If you can answer them, you are further along than you thought. If you can't, the gap between where you are and where this article argues you need to be is bigger than it looks from the outside.
One caveat. Most readers over-score. If you finished this and scored yourself 85, run it again with your Head of CS or Head of Product in the room. The gap between "we're working on it" and "it's in production generating attributable revenue" is where the real score lives.
The sequence matters more than any individual step. Doing this in the wrong order is the single most common reason intelligence initiatives stall.
Step 1. Get the room right. Assemble the cross-functional group. CEO, Product, CS, Design, Engineering. If any seat is vacant or unengaged, stop. Fill it first. This is the step that gets skipped and then blamed on the technology six months later. Cost: zero new hires. Calendar alignment. 1–2 weeks.
Step 2. Data audit. Inventory the cross-product data you already have that no competitor has. Inventory the tribal knowledge that is undocumented and should be. Most platforms discover their data is more fragmented than they assumed. Cost: internal data/analytics team, plus one external advisor if the stack is messy. 3–4 weeks.
Step 3. Pick the first prescription category. Not "add prescriptive intelligence to the roadmap." Pick one narrow category. Highest frequency, clearest attribution, most measurable outcome. In post-purchase, that's often sizing-driven returns. In marketing, budget reallocation. The first category is the proof of the architecture, not the whole product. Cost: a pod of 1 PM, 1 designer, 2 engineers, part-time data. 6–8 weeks to ship v1.
Step 4. Define the measurement framework. Three metrics, inside your core product analytics, not on a separate AI dashboard.
Cost: absorbed into the pod. 2 weeks, in parallel with Step 3.
Step 5. Launch the pricing tier. Ship a strategic intelligence tier as a premium SKU before the feature is fully built. Early access is how you build the proprietary dataset that makes the tier defensible.
Price it at 3–5x your current top tier. For mid-market customers, $2,000–$5,000/month. For enterprise cuts, $5,000–$10,000/month.
Cost: commercial team time. 2–3 weeks.
Step 6. Hire / Promote the Intelligence PM. Before your next feature PM. This is the highest-leverage external hire you will make in the next 18 months. Cost: senior PM comp plus a 20–30% premium. 2–4 months to hire well.
Step 7 — The 12-month arc.
By the end of this article, one of two things is happening. Either you've started mapping your team against the "who needs to be in the room" list.
Or you've pinged your CFO and asked what a six-person AI team would cost to run for a year.
Both are the right instincts. The answer to the second one is going to sting.
The in-house path. Building this internally, realistically, takes 8 to 12 months to reach a production-grade first category with attribution working. That means standing up a team roughly composed of 3 ML engineers, 2 data engineers, and 1 senior PM, fully loaded.
At mid-market comp that lands somewhere between $1M and $1.5M over the engagement, before you count the opportunity cost of the senior leaders pulled into the initiative. And that number assumes you hire correctly the first time, sequence the work correctly, and do not lose a quarter to integration drag. Most don't.
Roughly 70% of internal AI initiatives never reach ROI, not because the people are bad, but because the sequencing is wrong and the room was wrong at Step 1.
The Ionio path. We work with retail and e-commerce SaaS platforms in the $5M–$100M ARR range. The engagement runs 6 to 8 weeks from kickoff to a production-grade first prescription category with the measurement framework live and attribution wired in. Cost is structured as 5–10% of the attributable enterprise value increase generated by what we build, which is why we only take engagements where that math works for both sides.
The timeline difference is not because we work harder. It is because we have sequenced this repeatedly, we wrote the boilerplate that is now open source, and we wrote the article you are reading. You are hiring the compressed experience of all of it.
The Old Way
First-Year Fully Loaded Cost
Cash Out, Year One
Team You Have To Hire
3 ML engineers · 2 data engineers · 1 senior PM. Plus 4–6 months to hire them, plus the senior leaders you'll pull in to supervise.
of in-house AI initiatives never reach measurable ROI. Not because the people are bad. Because the sequencing was wrong at Step 1.
The Ionio Way
Of Attributable Enterprise Value Generated
Client Average
Return on engagement cost, measured against attributable enterprise-value increase over the engagement horizon.
Cash Out, Year One
Team We Embed
A senior squad that has sequenced this repeatedly. We wrote the open-source boilerplate. We wrote the article you're reading.
If you're at the point where you're deciding whether to build this internally from scratch or compress the timeline, this is the conversation we're built for. We’d love to chat. This would be a call directly with me (Rohan) & our product team. https://calendly.com/rohansawant/intro-meeting
Nothing in this article is a sure thing. Three things we're watching.
Approval volume. The feedback loop only compounds if users approve and reject prescriptions at high frequency. If they defer, ignore, or bulk-approve without reading, the training signal degrades and the walk stage stalls. We don't yet know what the floor rate is for the loop to work, and it probably varies by category and segment.
Long-horizon reasoning. Some prescription categories need to stitch together 6 to 9 months of customer history to produce a single recommendation. Current frontier models are close but not consistently reliable at that horizon. We expect this to resolve inside 18 months. Until it does, a few high-value categories stay gated.
Enterprise trust for auto-execute. Large enterprise customers may never hand graduation of prescriptions into autonomous execution to a vendor, regardless of approval history or attribution. If that's true, the walk stage becomes the ceiling in enterprise and the run stage lives only in mid-market. That changes the TAM of full autonomy meaningfully, and it changes who wins.

We were working with a SaaS client who made review software. A simple product for merchants that prompts their customers to leave reviews after a purchase. That is it. Collect reviews.
As we were building the AI features for them, we noticed something.
Their retention was excellent. Their LTV was better than almost any other company we had worked with.
When we dug into why, the answer was simple: no one had to log in.
The platform just worked. It collected reviews in the background. The merchant paid for it, got the outcome, and never thought about it. There was no dashboard to check, no tab to click, no weekly ritual of logging in to see numbers.
That realisation changed how we looked at every piece of software after that.
The best software is software you never need to log into.
Once you see it that way, you start to ask yourself, what even is the point of these dashboards?? Just tell me what I need to do…
We tried building a chatbot. It did work…kinda. The merchant could ask questions about their reviews, get strategy recommendations, surface patterns across their data. But the chatbot waited. It sat there until someone typed a question.
Most merchants do not have 20 minutes to interrogate a chatbot. They do not even know what questions to ask. The system already had the answers. But it just sat there.
“we can show them prompts on what to ask…” no that’s a duct-tape solution.
We threw out the chatbot and went back to first principles. If the system is smarter than the user, the system should lead. If it can see patterns across thousands of merchants, it should surface those patterns proactively. If it can estimate revenue impact, it should show that estimate alongside the recommendation.
If the action can be reduced to a single click, the button should sit right next to the evidence.
The system leads. The human responds.
The gap between what the software knows and what the user does with that knowledge is universal.
Every “data” platform is leaving money on the table because the last mile from data to decision is still being run by a human.
That became prescriptive intelligence.ai
that could not find a place inside the core structure of the article
1. The recommendations wave. Within 12 months of this article, at least two major SaaS platforms (any vertical) reposition their primary user-facing surface from a dashboard to a recommendations or prescription feed. The language will be "recommendations," "actions," or "insights." The architecture will be what we've described. Fermat is already there in its vertical. ActiveCampaign and Swap are shouting the intent. Others follow, quieter and faster than people expect.
2. The Intelligence PM gets named. Within 18 months, the first job postings for a role matching the profile in Section 8 show up at serious mid-market SaaS companies. The title is probably "AI Product Lead" or "Head of AI Product." Within 36 months it's standard at the top tier.
3. The pricing anchor moves. The first mid-market SaaS in retail/e-commerce to publish a strategic intelligence tier at 3–5x its current top price sets the anchor for the whole vertical. Everyone else is backfilling against that number inside 12 months of it landing, whether they rebrand their architecture or not.
You just read the whole sequence: the architecture, the six-step rollout, the room that has to be in it, and the Intelligence PM you probably don't have yet. It's a lot. The in-house path is 8–12 months and $1M–$1.5M before anyone approves a single prescription—and roughly 70% of those initiatives never reach ROI.
We compress that to a production-grade first category in 6–8 weeks. We've sequenced this repeatedly, we wrote the open-source boilerplate, and we wrote the article you just finished. You're not funding a hiring cycle or a learning curve—you're hiring the compressed experience of all of it, priced against the enterprise value it actually generates.
Why Ionio
Next Step
30 minutes, no deck. A call directly with Rohan and our product team—we'll pressure-test your data, your category, and whether the math works for both sides.
Book an Intro Call →