

The Real Problem with Speech Recognition Benchmarks
With so many speech-to-text (STT) models and APIs on the market today, you’d expect a clear, unbiased answer to the question: “Which one should I use?”But the truth is, it's far more complicated.
Academic research typically compares models, not production‑grade APIs. While these papers are useful for understanding model architectures and capabilities, they rarely reflect real-world performance or constraints. On the flip side, many API benchmarks found online are created by the providers themselves. And unsurprisingly they tend to rank their own solution at the top.Take Deepgram’s benchmark, for example: it places Deepgram first across all metrics. While that makes sense from a marketing standpoint, it’s not very useful for developers who just want an objective, reliable comparison based on actual performance in realistic scenarios.
Why We Did This Benchmark?
We needed something more practical and neutral. Our goal wasn’t to chase clicks or produce another glossy chart. We wanted to know:
Which speech-to-text model can actually be trusted when accuracy isn't optional?
We focused on real-world transcription challenges, especially in high-stakes environments like hospitals where a single error can have serious consequences. This benchmark is designed to help developers and product teams choose the right model for real-world speech not just the one that looks best in lab conditions.
Methodology
Dataset Description and Real-World Relevance
Our evaluation focused on real-world conditions that present significant challenges for speech recognition systems:
Dataset Overview:
- Total audio clips: 58
- Duration: 5 to 40 seconds per clip
- Categories:
- Clean Speech recorded in quiet, echo-free environments
- Noisy Speech includes real-world ambient noise like crowd chatter, movement, room reverb, or mild background static
- Speakers: Human-recorded audio clips sourced from workers using Ionio, covering diverse accents and speaking styles
- Format: WAV, 16 kHz, mono-channel (standard for most ASR systems)
Audio Specifications:
- Format: WAV
- Processing: Standardized to 16 kHz sGitHub Repositoryample rate for model compatibility
- Variety: Diverse accent patterns and environmental conditions
- Challenge level: High combining accent variation with noise interference
You can checkout and use our dataset linked here: Speech to Text Benchmark
Checkout the GitHub Repository: Ionio GitHub
Evaluated Models
We tested seven leading speech-to-text models representing different approaches to automatic speech recognition:
Whisper (OpenAI) – High accuracy in clean speech, strong multilingual support, available in multiple sizes (tiny, base, small, medium, large).
Deepgram – Excels in real-time transcription and noisy environments, with low latency.
AssemblyAI – High accuracy in clean and noisy speech, strong formatting capabilities.
Wav2Vec2 – offers versatility, with facebook/wav2vec2-large-960h-lv60-self for custom ASR systems, integrating seamlessly with Hugging Face.
Distil-Whisper – is 6x faster and 49% smaller, performing within 1% WER of Whisper, ideal for resource-constrained applications, as seen in distil-whisper/distil-large-v3.
NVIDIA Parakeet 0.6B v2 – Nvidia's fast and efficient, research-grade model with 0.6B parameters.
IBM Granite‑speech‑3.3 – High‑accuracy closed‑weight model with state‑of‑the‑art deletion and WER performance with 8B parameters.
Evaluation Metrics
Word Error Rate (WER) was our primary evaluation metric, as it's widely used to quantify transcription accuracy. However, we went beyond WER by also analyzing the specific types of errors that contribute to it: substitutions, deletions, and insertions. These individual components often have outsized effects in real-world use cases.
WER = (S + D + I) / N × 100%Where:
- S = Number of substitutions (incorrect words)
- D = Number of deletions (missing words)
- I = Number of insertions (extra words)
- N = Total number of words in ground truth
Lower WER indicates better transcription quality, with 0% WER representing perfect accuracy.
Significance of Error Types in Domain-Specific Applications
While WER gives a summary view, understanding how a model makes mistakes is just as important especially in domains like healthcare, law, or live broadcasts where each word may carry critical meaning:
Substitution (S): Replacing "dose" with "those" in a medical instruction like "Give 50 mg dose" → "Give 50 mg those" could cause dangerous confusion.
Deletion (D): Omitting "not" in "Do not resuscitate" → "Do resuscitate" flips the intent entirely.
Insertion (I): Adding "no" in "The test was positive" → "The test was no positive" introduces ambiguity or contradiction.
We also tracked Character Error Rate (CER) to capture more granular errors in spellings or names important for applications like transcribing names, emails, or short codes.
Inference Strategy: Multi-Pass vs. Zero-Pass Inference
To better understand model stability and variability, we evaluated open-source models under two inference setups:
For models like Whisper, Distil-Whisper, Wav2Vec2, and Parakeet, we averaged results over three inference passes using a temperature of 0.3. This better reflects real-world usage where slight variability across runs may occur due to sampling or decoding noise. It also smooths out occasional outliers in prediction.
All models including proprietary APIs like AssemblyAI, Deepgram Nova-2, and Granite were evaluated once with deterministic decoding (no randomness) for direct head-to-head comparison. This ensures that open and closed models are judged fairly under identical constraints.
By including both inference modes, we provide a richer benchmark:
- The multi-pass scores highlight how well models perform when tuned for robustness.
- The zero-pass scores test raw performance under strict, real-time conditions.
Noise Augmentation Strategy
Our augmentation pipeline was designed to simulate diverse acoustic distortions:
Gaussian NoiseAdded to every sample in the noisy set. Noise amplitude was randomly drawn between 0.001 and 0.015, simulating varying levels of low-to-moderate environmental interference.
Time Stretching (50% probability)Speed altered between 0.8× (slower) and 1.25× (faster). This tested models' ability to handle speaking rate variations.
Pitch Shifting (50% probability)Altered pitch by ±4 semitones, mimicking speaker diversity in tone, age, and emotion.
Together, this created a synthetic but plausible noisy dataset. This setup helped separate models that only perform well under ideal lab conditions from those that generalize in real-world scenarios.
Benchmark Analysis Results For Open-Sourced Models
Clean Speech Evaluation
For clean audio conditions, the results show a clear performance hierarchy among the tested models. Granite-Speech-3.3 emerged as the standout performer with an exceptional 8.18% WER, significantly outpacing all competitors. The model demonstrated remarkable consistency with low standard deviation, making it highly reliable for clean speech transcription tasks.
Distil-Whisper secured second place with a respectable 14.93% WER, offering a good balance of accuracy and efficiency. The standard Whisper model followed closely at 19.96% WER, while Parakeet delivered solid performance at 18.56% WER.
Wav2Vec2 struggled considerably in this category, posting a disappointing 37.04% WER - nearly three times worse than the leading model, indicating significant challenges with clean speech recognition.
Noisy Speech Evaluation
The introduction of background noise revealed interesting shifts in model robustness. Granite-Speech-3.3 maintained its leading position with 15.72% WER, demonstrating exceptional noise resilience with only a 7.54% performance degradation from clean conditions.
Distil-Whisper showed strong noise handling capabilities, achieving 21.26% WER - a modest 6.33% increase from clean speech. Parakeet exhibited similar resilience at 21.58% WER, while standard Whisper experienced more significant degradation, jumping to 29.80% WER.
Wav2Vec2 remained the weakest performer at 54.69% WER, with noise conditions exacerbating its already poor performance by an additional 17.65%.
%20(1).png)
%20(1).png)
Error Pattern Analysis
The detailed error breakdown reveals distinct behavioral patterns across models, each with specific use case implications:
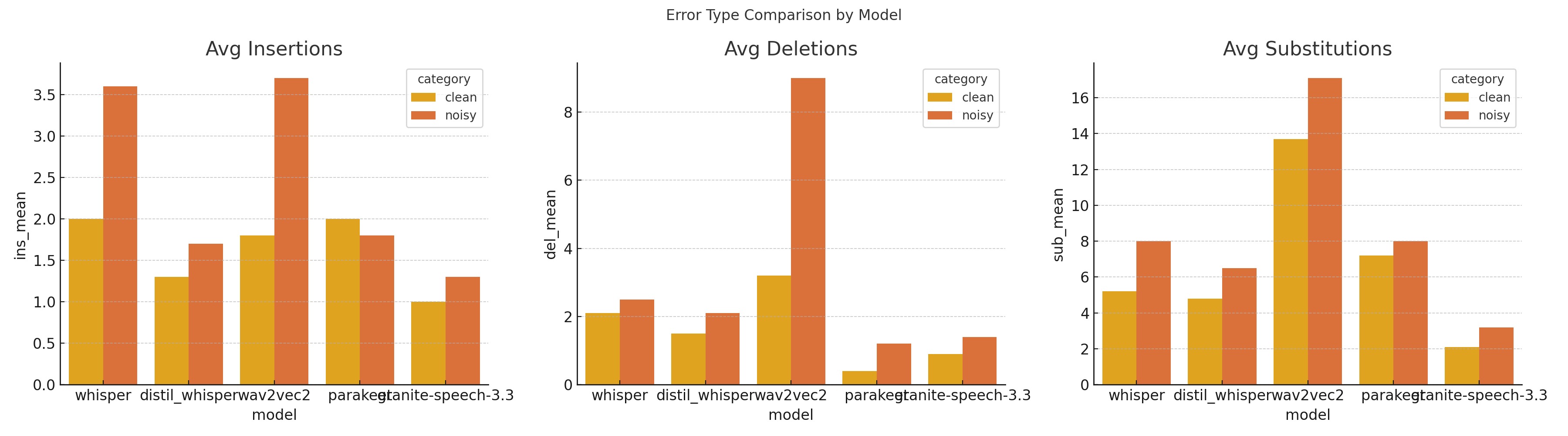
Insertion Errors
Insertion errors occur when a model adds extra words that were not present in the original speech. These phantom words can severely impact applications like live captioning or voice command systems, where precision is essential.
Granite-Speech-3.3 demonstrated minimal insertion errors 0.828 in clean conditions and 0.862 in noisy conditions highlighting its precision in preserving intended content. This makes it especially suitable for real-time systems that demand accuracy, such as broadcast captioning or in-car voice controls. AssemblyAI and Parakeet also maintained low insertion error rates around 1.0 to 1.1, offering dependable performance for similar use cases.
Whisper, however, showed a sharp increase in insertion errors under noisy conditions, reaching 2.362. This could result in potentially disruptive false positives, such as transcribing “call John” as “call John now,” which could mislead a voice assistant. Wav2Vec2 performed poorly even in clean conditions with an insertion error rate of 2.017, which already makes it unsuitable for applications where added words could distort meaning.
Overall, Granite-Speech-3.3 and Distil-Whisper consistently maintained low insertion errors across conditions, making them strong candidates for real-time transcription systems. In contrast, Whisper and Wav2Vec2 demonstrated vulnerabilities in noisy settings that could compromise reliability in voice-activated or real-time scenarios.
.png)
Deletion Errors
Deletion errors occur when a model omits words that were present in the original audio. These are particularly damaging in domains like medicine or law, where every word carries weight.
Parakeet led the field in this category, posting a deletion error rate of just 0.414 under clean conditions. This makes it well-suited for controlled environments where completeness is non-negotiable. Granite-Speech-3.3 also performed well, maintaining a 1.328 deletion error rate in noisy conditions an impressive feat that supports its use in scenarios such as emergency call transcription or on-field interviews.
Wav2Vec2, in contrast, had a deletion rate of 8.897 under noise, which suggests a frequent tendency to drop entire phrases. This level of omission could be disastrous in critical situations, such as omitting the word “not” in a phrase like “do not resuscitate.”
Parakeet’s consistent strength in minimizing deletions makes it the best fit for medical, legal, and accessibility-focused applications. Wav2Vec2’s extreme drop in performance under noise renders it unsuitable for use cases where completeness of information is essential.
.png)
Substitution Errors
Substitution errors involve replacing a correct word with an incorrect one. This kind of error is particularly dangerous in high-accuracy fields like finance, law, or customer support, where a single word change can alter the meaning significantly.
Granite-Speech-3.3 again led with the lowest substitution rates, scoring 2.276 in clean and 3.276 in noisy conditions. These low values demonstrate its ability to preserve content integrity, making it a top choice for transcribing stock trading conversations, legal depositions, or support call recordings.
Distil-Whisper delivered moderate substitution rates, which makes it well-suited for educational content or podcast transcriptions where occasional inaccuracies are tolerable. On the other hand, Wav2Vec2’s substitution error rate ballooned to 13.879 under noisy conditions. Such high substitution frequency could distort key terms for instance, misreporting "profit" as "loss" leading to serious misunderstandings in professional contexts.
In summary, Granite-Speech-3.3 remains the most reliable model across all error types, especially in environments demanding high accuracy. Distil-Whisper provides a balanced alternative for less sensitive content, while Wav2Vec2’s high substitution and deletion rates indicate that it is not a viable option for production-grade transcription.
.png)
Performance in Noisy Conditions
Robustness in noisy environments is key for real-world applications. Here's how errors change from clean to noisy conditions:
Noise Robustness Insights
Granite-Speech-3.3's modest 3.5% WER increase underscores its superior noise-handling, likely due to an architecture optimized for distinguishing speech from diverse background noises (e.g., traffic, crowds), making it a prime candidate for outdoor event captioning or noisy workplace transcription. Wav2Vec2's 20.7% surge suggests a training bias toward clean audio, failing to generalize to real-world noise types, such as overlapping voices or mechanical hums, limiting its utility outside pristine conditions.
Insight: Granite-Speech-3.3 and Distil-Whisper show moderate increases, indicating robustness. Parakeet's unique decrease in insertion errors under noise is notable, while Wav2Vec2's massive deletion spike and Whisper's insertion surge highlight their weaknesses in noisy settings.
Character vs Word Error Analysis
The correlation between Word Error Rate (WER) and Character Error Rate (CER) showed strong alignment across models, with a correlation coefficient of 0.691. This suggests that models with poor word-level performance also struggle with character-level accuracy.
Granite-Speech-3.3 achieved the best CER performance (10.26% overall), while Distil-Whisper led in pure CER metrics (10.14%), demonstrating excellent character-level precision.
.png)
.png)
Use Case Recommendations
Based on the error patterns and overall performance (WER: Granite-Speech-3.3 at 0.1195, Distil-Whisper at 0.1809; CER: Distil-Whisper at 0.1014, Granite-Speech-3.3 at 0.1026), here's how the models align with specific applications:
Granite-Speech-3.3:
- Strengths: Lowest WER (0.1195), low substitution (~3.09) and insertion (~1.37) errors.
- Best for: Financial services transcription, customer service analytics, and legal documentation requiring high accuracy and robustness.
Distil-Whisper:
- Strengths: Lowest CER (0.1014), balanced insertion (~1.50) and substitution (~5.73) errors.
- Best for: Educational content transcription, podcast/media subtitling, and live captioning where clarity and moderate noise resilience are key.
Parakeet:
- Strengths: Lowest deletion errors (~0.80), moderate WER (0.2007).
- Best for: Medical transcription and accessibility applications where missing words are unacceptable; also viable for general meeting transcription.
Whisper:
- Strengths: Moderate overall performance (WER 0.2488, CER 0.1494).
- Best for: Interview documentation and meeting notes where context tolerates higher substitution (~7.36) and insertion (~2.79) errors.
- Weakness: Poor in noisy conditions for insertion-heavy applications.
Wav2Vec2:
- Weaknesses: Highest WER (0.4587), CER (0.8679), and error rates (substitution ~15.28, deletion ~5.94).
- Not recommended for production use due to unreliability, especially in noisy environments.
Benchmark Analysis Results for All Models
Clean Speech Evaluation
In clean audio conditions, the performance hierarchy of the models is evident based on Word Error Rate (WER):
Insight: Granite-Speech-3.3's exceptional 7.9% WER positions it as the leader, significantly outpacing competitors by at least 1.5 percentage points. This low error rate reflects its ability to accurately transcribe speech in ideal conditions, making it highly reliable for precision-driven applications such as legal documentation, where every word must be captured correctly to avoid misinterpretation in contracts or court records, or medical transcription, where errors could lead to incorrect patient records or treatment plans. AssemblyAI and Parakeet, with WERs of 9.4% and 9.5% respectively, also perform admirably, offering viable alternatives for similar high-stakes tasks, though with slightly less consistency. Granite-Speech-3.3's performance suggests robust training on diverse clean speech datasets, ensuring minimal errors across varied speakers and vocabularies. In contrast, Wav2Vec2's 29.0% WER indicates significant struggles, likely due to limitations in its architecture or training data, rendering it impractical for applications requiring high accuracy in controlled environments.
Noisy Speech Evaluation
Background noise challenges the models' robustness, shifting their performance:
Detailed Insight: Granite-Speech-3.3 maintains its dominance with an 11.5% WER in noisy conditions, experiencing only a modest 3.5% increase from clean audio. This resilience highlights its advanced noise-suppression capabilities, likely stemming from a well-designed architecture that effectively filters background interference, making it an excellent choice for real-world scenarios like live captioning in bustling environments (e.g., conferences or public events) or call center transcription amidst ambient chatter. AssemblyAI's 14.1% WER (+4.7%) also demonstrates notable robustness, suitable for similar noisy applications where slight accuracy trade-offs are tolerable. Conversely, Wav2Vec2's drastic jump to 49.6% WER (+20.7%) reveals a critical weakness in handling noise, possibly due to overfitting to clean data or inadequate noise-augmentation during training, making it unreliable for any practical use in non-ideal settings. The moderate increases for Parakeet (6.7%), Distil-Whisper (6.1%), and Deepgram (7.1%) suggest decent adaptability, though they lag behind the top performers in maintaining accuracy under adverse conditions.
.png)
Error Pattern Analysis
Analyzing insertion, deletion, and substitution errors provides deeper insight into model behavior and application suitability.
Insertion Errors
Insight: Insertion errors, where extra words are added, can severely impact applications like voice command systems (e.g., smart assistants) or live captioning, where unintended words could trigger incorrect actions or confuse viewers. Granite-Speech-3.3's minimal insertion rates (0.828 in clean, 0.862 in noisy) showcase its precision in avoiding phantom words, making it ideal for real-time systems requiring exact transcription, such as broadcast captioning or automotive voice controls. AssemblyAI and Parakeet, with rates around 1.0-1.1, also perform well, offering reliability for similar uses. Whisper's sharp increase to 2.362 in noisy conditions signals a vulnerability that could lead to significant disruptions, such as misinterpreting "call John" as "call John now" in a voice assistant, while Wav2Vec2's high clean-condition rate (2.017) already disqualifies it from precision-critical tasks.
Deletion Errors
Insight: Deletion errors, where words are omitted, are critical for tasks requiring full transcription, such as medical transcription or legal proceedings. Parakeet's standout 0.414 rate in clean conditions makes it a top choice for controlled settings, ensuring vital terms like "dosage" or "testimony" aren't missed, which could have severe consequences. Granite-Speech-3.3's 1.328 in noisy conditions reflects its ability to preserve completeness even under interference, fitting it for field interviews or emergency call logs. Wav2Vec2's alarming 8.897 in noise indicates a propensity to skip entire phrases, rendering it useless for any application where missing information could alter meaning or outcomes, such as omitting "not" in "patient is not responding."
Substitution Errors
Insight: Substitution errors, where words are replaced incorrectly, affect applications like financial transcription or customer service analytics, where precision in terminology (e.g., "buy" vs. "sell") is paramount. Granite-Speech-3.3's low rates (2.276 clean, 3.276 noisy) ensure accurate capture of key terms, making it ideal for stock trading logs or support call analysis. AssemblyAI's 3.948 in noise remains competitive, supporting similar uses with minor trade-offs. Wav2Vec2's 13.879 in noisy conditions could disastrously misrepresent data, such as transcribing "profit" as "loss," highlighting its unsuitability for high-accuracy needs.
Performance in Noisy Conditions
WER increases reveal robustness:
Insight: Granite-Speech-3.3's modest 3.5% WER increase underscores its superior noise-handling, likely due to an architecture optimized for distinguishing speech from diverse background noises (e.g., traffic, crowds), making it a prime candidate for outdoor event captioning or noisy workplace transcription. AssemblyAI's 4.7% rise also indicates strong noise resilience, suitable for semi-controlled settings like cafeteria interviews. Wav2Vec2's 20.7% surge suggests a training bias toward clean audio, failing to generalize to real-world noise types, such as overlapping voices or mechanical hums, limiting its utility outside pristine conditions.
Overall Model Rankings
.png)
Average WER across conditions:
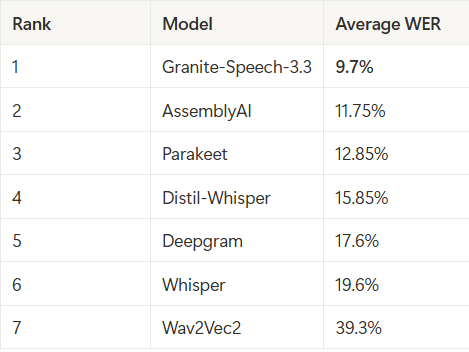
Insight: Granite-Speech-3.3's 9.7% average WER reflects its consistent excellence across clean and noisy scenarios, offering unmatched versatility for enterprise-grade transcription spanning diverse environments. AssemblyAI and Parakeet, at 11.75% and 12.85%, provide reliable alternatives with narrower strengths. Wav2Vec2's 39.3% average confirms its poor overall performance, lacking the stability needed for dependable deployment.
Limitations of This Benchmark
- Small Dataset Size
The benchmark uses only 58 audio clips, which limits the statistical significance of the results. Larger and more diverse datasets would provide a more comprehensive evaluation across different speech types and conditions.
- English-Only Evaluation
All evaluations were done on English audio. This excludes insights into how multilingual models perform in non-English scenarios, limiting the benchmark’s global applicability.
- No Conversational or Overlapping Speech
The dataset consists of clear, single-speaker recordings. It does not test how models perform with overlapping speech, turn-taking, or interruptions commonly found in real-world conversations.
- Limited Accent Representation
While diverse accents were included, the sample size per accent group was too small for reliable fairness analysis. Accent bias remains an important consideration in production systems.
- No Domain-Specific Vocabulary
The benchmark does not include technical or domain-specific terms from areas like healthcare, law, or finance. Models may require fine-tuning for specialized transcription tasks.
- No Speed or Latency Testing
The focus was on transcription accuracy. Inference time, responsiveness, and compute efficiency critical for real-time applications were not measured or compared.
- No Prompt or Context Optimization
All models were tested in zero-shot mode without prompt engineering or conversational context. Some models may achieve better results with contextual cues or metadata.
Key Insights and Use Case Recommendations
Based on the error patterns and overall performance (WER: Granite-Speech-3.3 at 0.1195, Distil-Whisper at 0.1809; CER: Distil-Whisper at 0.1014, Granite-Speech-3.3 at 0.1026), here's how the models align with specific applications:
Granite-Speech-3.3
- Strengths: Lowest WER (0.1195), low substitution (~3.09) and insertion (~1.37) errors; noise-robust
- Best for: Mission-critical tasks (medical transcription, legal documentation, financial services, live accessibility) due to its precision and adaptability
- Detailed Insight: Its balanced performance across error types and conditions makes it a go-to for high-stakes applications where errors could lead to legal disputes, medical mishaps, or financial losses
AssemblyAI
- Strengths: Low insertions/substitutions in noise
- Best for: Live captioning, voice commands
- Detailed Insight: Its noise resilience and minimal extra words suit real-time uses where clarity and responsiveness outweigh occasional omissions
Parakeet
- Strengths: Lowest deletion errors (~0.80), moderate WER (0.2007); lowest clean-condition deletions
- Best for: Medical transcription and accessibility applications where missing words are unacceptable; also viable for general meeting transcription
- Detailed Insight: Its completeness in ideal conditions supports tasks where every word counts, though noise performance limits broader use
Distil-Whisper
- Strengths: Lowest CER (0.1014), balanced insertion (~1.50) and substitution (~5.73) errors
- Best for: Educational content transcription, podcast/media subtitling, and live captioning where clarity and moderate noise resilience are key
- Detailed Insight: Moderate accuracy fits non-critical transcription where cost or speed may prioritize over perfection
Deepgram
- Best for: Educational content, podcasts
- Detailed Insight: Moderate accuracy fits non-critical transcription where cost or speed may prioritize over perfection
Whisper
- Strengths: Moderate overall performance (WER 0.2488, CER 0.1494)
- Best for: Interview documentation, meeting notes, and non-critical meetings where context tolerates higher substitution (~7.36) and insertion (~2.79) errors
- Weakness: Poor in noisy conditions for insertion-heavy applications
- Detailed Insight: Balanced but average performance suits casual uses, with noise-induced insertions a notable drawback
Wav2Vec2
- Weaknesses: Highest WER (0.4587), CER (0.8679), and error rates (substitution ~15.28, deletion ~5.94)
- Not recommended for production use due to unreliability, especially in noisy environments
- Detailed Insight: Its consistent underperformance, especially in noise, makes it impractical for production, risking significant inaccuracies
What's Next?
Still unsure which speech-to-text model best fits your needs? Book a call with us to dive deeper into our benchmarking insights and identify the perfect model, whether it's Granite-Speech-3.3 for mission-critical accuracy or a proprietary alternative like AssemblyAI or Parakeet for specific use cases. Let's pinpoint the ideal solution for your transcription demands, from live captioning to medical records. Ready to move forward?
Request a tailored benchmarking analysis or Book a call to pinpoint the right model for your use case be it live captioning, voice agents, or clinical transcription.





.png)
.png)

